
How Will Generative AI Change the Practice of Data Science


TL;DR
Generative AI (GenAI) has the potential to disrupt labor markets across the world. In this post, I discuss its impact on the practice of data science. I start by examining the fundamental principles of GenAI, which I consider to be: (i) information retrieval, (ii) language understanding and generation, (iii) generality and flexibility, and (iv) actions. In light of these principles, there will be considerable human augmentation in the short run, with data scientists experiencing a productivity boost beyond their programming capabilities. In the medium term, I envision a nascent type of task specialization, with humans specializing in analytics and business understanding. However, an expert data scientist will need to supervise the tasks performed by the AI. In the long run, I expect to see a complete transformation of the role, with full unsupervised task specialization.
Introduction
Last week I attended the Latam Impulse Data & AI Conference, where I had the opportunity to share my thoughts on the impact that generative AI (GenAI) may have on the practice of data science. The presentation I gave was based on Chapter 17 of Data Science: The Hard Parts (THP), but I decided to depart and make some points that at the time I finished the book were not clear to me yet. In this post I want to share the main points of the talk to a wider audience, and expand on some of the topics that generated more discussion.
Why is this question relevant?
I started working on THP back in October 2022 (Figure 0). The book had already been designed and approved, and would include 16 chapters on techniques to help data scientists become more productive. ChatGPT was launched on November 30, and it basically went unnoticed to me for the rest of that year. I played with it a bit, but I wasn’t impressed, and I completely dismissed it.

GPT-4 was launched in March 2023, and now it did capture the attention of everyone. I tested it with coding prompts, and while I thought it was cool and impressive, I didn’t plan to use it since it felt that it took away the pleasure of writing code yourself (the struggle and excitement when your code finally works as planned).
A few weeks later I had my Aha! moment, again with a coding problem. This time I had no extra time to spend on this problem I had solved years earlier, but I just couldn’t make it work now. I had a mind blowing conversation with ChatGPT, where after iterating several times, we got to the solution together. It felt like discussing a problem with a colleague, and my colleague was a really capable one.
I became a frequent user, and some months later, when the book was almost finished, it finally struck me that the contents of THP might become obsolete soon enough if GenAI kept advancing at the same pace. I decided to make an evaluation, and that’s how the last chapter of the book came about.
What is GenAI?
In the past I’ve written somewhat technical posts about LLMs and their inner workings. For the purposes of this post, I find it more productive to zoom out and try to focus on the main principles behind GenAI (Figure 1).

Information retrieval
One of the things that’s most impressive about GenAI, is that they seem to know a lot about many things. And it’s not surprising since they are trained with massive datasets, including most of what’s been written on the web, as well as the publicly available images and videos.
It’s almost comical that a model designed to predict the next word, can memorize the whole of the internet once they reach a large enough scale, and exhibit some emergent behaviors for which it was not designed. This property is so important, that it has the potential to completely disrupt the multibillion dollar search and advertising industries.1
But as we know, these models can behave as stochastic parrots and may “hallucinate”, producing incorrect answers to our inquiries. The solution has been to specialize the search using external knowledge bases, powered by vector databases that aim at finding similar texts or concepts (RAG).
Understanding and generation
The second principle behind GenAI is its ability to understand and generate language. If you compare GPT-4 with Siri or Alexa, it feels like the latter are artifacts from a distant past, And what started as a text-only interface, has quickly become multimodal. You can now share an image to Bard or GPT-4, and soon enough we’ll start seeing interfaces for videos too.
Generality and flexibility
Before the GPTs, models had to be tailored to specific problems. For instance, if you needed a model for machine translation or text classification, each required a specific architecture and implementation. The new generation of GenAI is built on a transformer-based architecture, and their massive scale has provided enough generality to solve many problems at once. It’s not yet fully “general purpose”, but the results show that it performs as well as humans across many benchmarks.
Execute actions
Many companies struggle with implementing GenAI use cases internally, mostly because it’s far from obvious how to get them to act upon the recommendations it gives (even without hallucinating). One solution is to make the GenAI write code that can execute external APIs. It’s still early on to call this an “underlying principle” of GenAI, but we should expect it to become the norm in the future.2
My predictions
Thinking in terms of underlying principles allows us to set aside practical blockers in current implementations, and project the potential impact of GenAI into the future. For my current purposes, I find it productive to think in terms of short, medium and long term predictions (Figure 2).
I’ll first define these terms, since they mean different things to different people. The short term is what we can do now. The medium term includes things that the current technology will be able to do without major improvements. There are already many startups working on the problems that will be solved in the medium term. The long term is, by definition, long enough for many changes to happen, but not too long that artificial general intelligence (AGI) has already been developed.3

Short term: human augmentation
In the short term, GenAI is here to make you substantially more productive. The starting place for data scientists is in writing code, but there are many other places where GenAI helps you in becoming a 10x data scientist.
Figure 3 shows some of the tasks where GenAI can help you today. Just by making you a more effective coder, you’ll see that your productivity is multiplied elsewhere, since data scientists use coding for anything from data wrangling and data collection, to developing and deploying machine learning (ML) models, creating data visualizations for storytelling purposes, and the like.

But Figure 3 shows other less common tasks, like coming up with ideas for solutions and proposals, better understanding of the business, communicating skillfully, and others.
In the short term, the main principles used for human augmentation are information retrieval, language understanding and generation, and generality. Only relatively simple tasks (like function calling with OpenAI) will make use of the ability to execute actions. Agents will only become critical in the medium and long terms.
Medium term: task specialization
In the medium term I predict there will be more specialization in tasks. In a highly discussed paper, Eloundou, et.al. (2023), look at the degree of AI exposure of tasks. They define exposure “as a proxy for potential economic impact without distinguishing between labor-augmenting or labor-displacing effects”.
Figure 4 summarizes their findings on the correlation between skills and exposure. Note that exposure is defined for tasks, but we can infer the relative exposure of skills if we estimate the former.
Data science requires some of the less exposed skills, such as having a scientific mindset, active learning4, critical thinking5, monitoring6. On the other hand, programming is the most exposed skill of all.

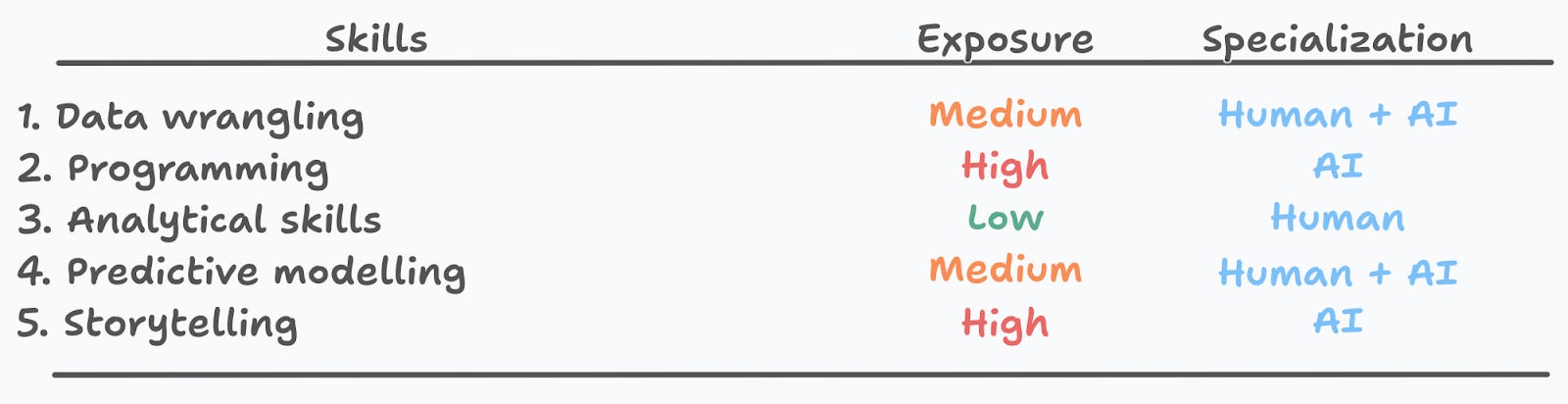
In Figure 5 I show the top skills I think a data scientist should have, and my subjective exposure evaluation, each associated with a level of human/AI specialization.
I evaluate data wrangling with a medium level of exposure, since I believe that one part (the more “operational”) can be done and automated by AIs, but we will still require humans to assess whether the outcome makes sense from a business standpoint.
Programming will no longer be a key differentiator, and in the medium term anyone will be able to provide instructions (no-code, or natural language) that a machine can easily translate into code. Humans will then evaluate if things make sense or not.
Analytical skills are inherently human, and combine all of the skills with low exposure in Figure 4. To me, this suggests that our main competitive advantage, what makes us truly different from AIs, is our ability to think analytically.
Predictive modeling also has a medium exposure score. The hard part of building ML models is related to the scientific mindset, but there are many parts of the ML workflow that can be easily left to AIs (sample splitting, cross-validation, algorithm selection, training and prediction). Opening the black box and checking if things make sense are inherently human abilities.
Finally, I think that storytelling will become less important in the medium term, and we will mostly be able to let AIs write up reports and presentations. Note that this is the more conventional use of the word, the one closer to the sales-person persona. I exclude the broader one that also includes the scientist-persona, included in the analytical skills category.
Long term: transformation
In the long term, I envision the specialization phase continuing and deepening to the point where the role of a data scientist, as we currently know it, ceases to exist. To me, the best world is a business scientist, and if I have to bet on the future of the role, I’d bet on it. (Figure 6).
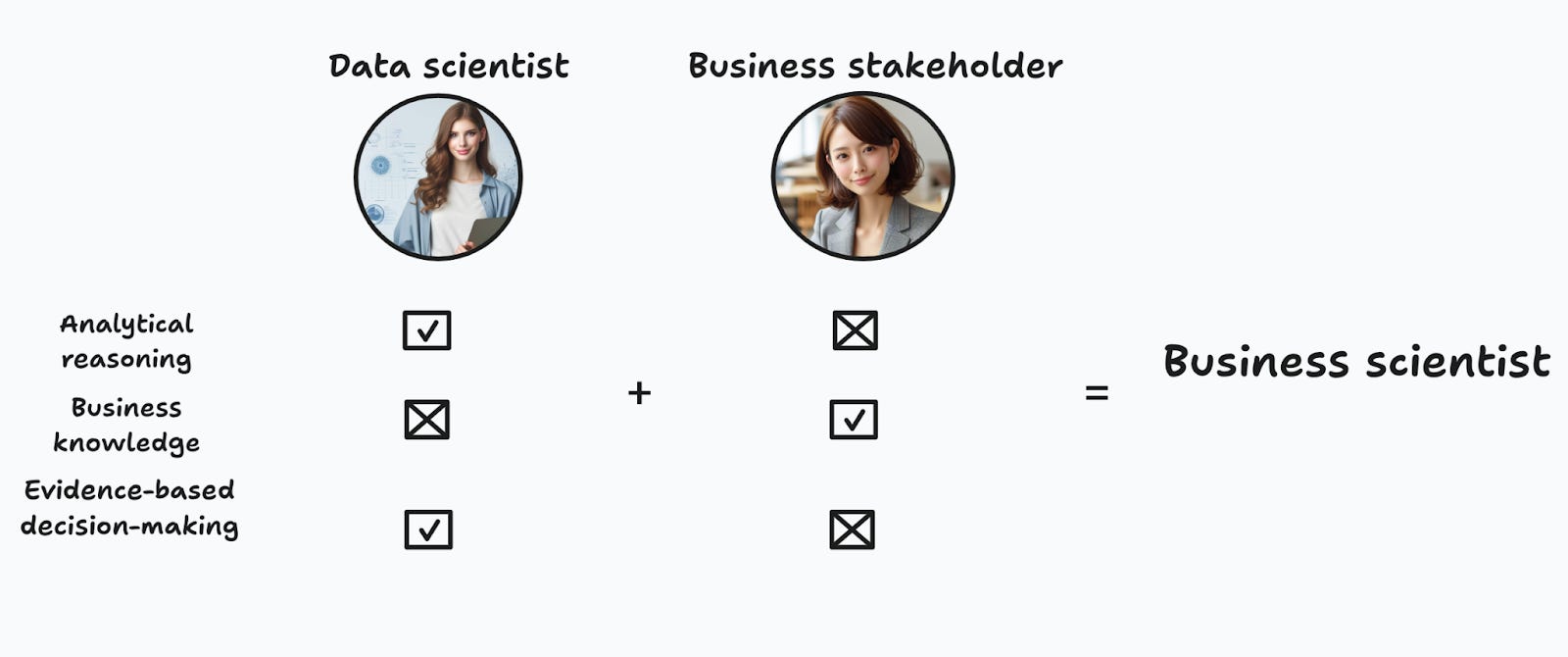
In Chapter 17 of THP I actually entertained the question of what’s easier: endowing a data scientist with a scientific mindset and knowledge of the business, or endowing a business stakeholder with the required analytical skills and scientific mindset. I just couldn’t come up with a convincing answer, so I thought the best was to come up with a new role altogether. This is the business scientist.
Final thoughts
I should start this last section with a first natural disclaimer: making predictions about the future of AI is almost impossible since things are moving just too fast. This is my current assessment, and while I think it’s directionally correct, the medium and longer term might take longer than expected, or AGI might arrive sooner than expected.
That is my second disclaimer: AGI is such a game changer, that all of these predictions make little sense if we develop AGI soon.
The third disclaimer is more of a suggestion for aspiring data scientists: at this point in time, you need to keep investing in the technical skills that are highly exposed to AI. Put differently, you need to become great programmers and learn your ML thoroughly. But I’d also start investing in acquiring analytical skills and learning causal inference, since those are the main differentiators in the future, and today (but your hiring managers may not know this yet).
There are many startups entering this stage, but one worth checking out is perplexity.ai.
AGI is the state where a computer can do most things that humans do. OpenAI’s mission is to develop safe AGI, and recently, Shane Legg, Deep Mind’s Chief AGI Scientist estimated that there’s a 50% chance that humans develop AGI as early as 2028.
“Understanding the implications of new information for both current and future problem-solving and decision-making.”
“Using logic and reasoning to identify the strengths and weaknesses of alternative solutions, conclusions or approaches to problems.”
“Monitoring/Assessing performance of yourself, other individuals, or organizations to make improvements or take corrective action.”