


In my last post, I discussed deep reinforcement learning (RL) in the context of sequential decision making, and argued that it arises very naturally in many settings. One application of RL where it’s not obvious that the sequential decision-making applies is Reinforcement Learning with Human Feedback (RLHF). In this post I’ll discuss RLHF and some of the puzzles around it.
Setting up the stage: Pretraining
More than a year after its launch, almost everyone has heard about ChatGPT and many have even become recurrent users. The GPT in ChatGPT stands for Generative Pretraining Transformer. It’s generative because you can create new content (text) with it, it uses transformers as the main component in the decoder-only architecture, and it’s pretrained because it goes first through a semi-supervised phase that can then be finetuned in later stages.1
During the pretraining stage, we start with a vast corpus of data and aim to predict the next word or token given the preceding context:
This pretraining stage is data (and compute) intensive. For example, Llama-2 was trained on 2T tokens, or around 1.5T words. If the average book has 75K words, this amounts to being trained on 20M books! If you read 50 books per year, it would take you 400K years to go through the entire corpus used to train Llama-2.
Generally speaking, during pretraining, an autoregressive model learns the underlying language representations necessary to predict the next word. These include things like:
Semantics: what is the meaning of words, and how does this vary across different contexts.
Syntactic rules: how can we combine words, what is the relationship between different types of words (nouns, verbs, etc.), and more generally, what are the compositional rules that make a language.
Behavioral rules: the rules that apply on a social network like X need not apply elsewhere, so the diversity of social contexts implicit in a corpus will affect the next-word prediction.
Reasoning: how we express ourselves also provides information on how we reason, and this knowledge is useful when predicting the next word.
Stuff: we memorize stuff, like “Paris is the capital of ____”. The model may not know what this stuff means, but it is still memorized.
Intentions: take the case of “Someone needs to be ___”. For instance, if you know that the speaker is angry you might predict something like “reprimanded”.
At least from an interpretability point of view, it would be great if we were able to disentangle each of these dimensions (and any others), or even train submodels that specialize on each one (and find a way to coordinate them). But large language models (LLMs) are black boxes, and the field of interpretability for deep neural networks is still in its infancy.2 This means that while you can get pretty decent answers if you ask a question to a model, there’s no guarantee that the answer will be helpful, honest and harmless (the three H’s in AI alignment).
Specializing the model for a task: finetuning
These stochastic parrots are so powerful that they can pass a Turing test and fool you to believe that you’re speaking with a human. But if you play with them long enough, you’ll find that many times they regurgitate nonsensical information. To make LLMs useful we need to move one step forward, to supervised finetuning (SFT).
As the name suggests, we move away from semi-supervision to full blown supervision, and thus, we require labeled data. Unfortunately, labeled data is hard to come about, so you may now expect that datasets to be smaller. Going back to Llama-2, it used 100K tokens, down from the 2T tokens used in pretraining.
Moving from pretraining to SFT is not obvious, since we want to use the parameters learned during pretraining and adapt them to the specialized task. But these parameters can’t just be used as knowledge, as they pertain to a specific architecture. So if we want to use these parameters we need to somehow maintain the architecture.
Not so long ago, in the BERT days, one could replace a head from the pretrained encoder model with a specialized task head such as a classification, for sentiment analysis.3 In practice, we use the learned representations (and thus, parameters) of the encoder block, remove some part of the architecture, and adapt the head for our classification task.4
We can adapt this same idea to autoregressive models. In “Improving Language Understanding by Generative Pre-Training”, Radford, et.al. (2018) start with a decoder-only autoregressive model like the one used in the GPTs (left side of Figure 0), and feed the last hidden layer from the transformer blocks into a linear layer. Put differently, they use most of the architecture (the transformer blocks that lead to the last hidden layer), and replace the head, just as was done with BERT.
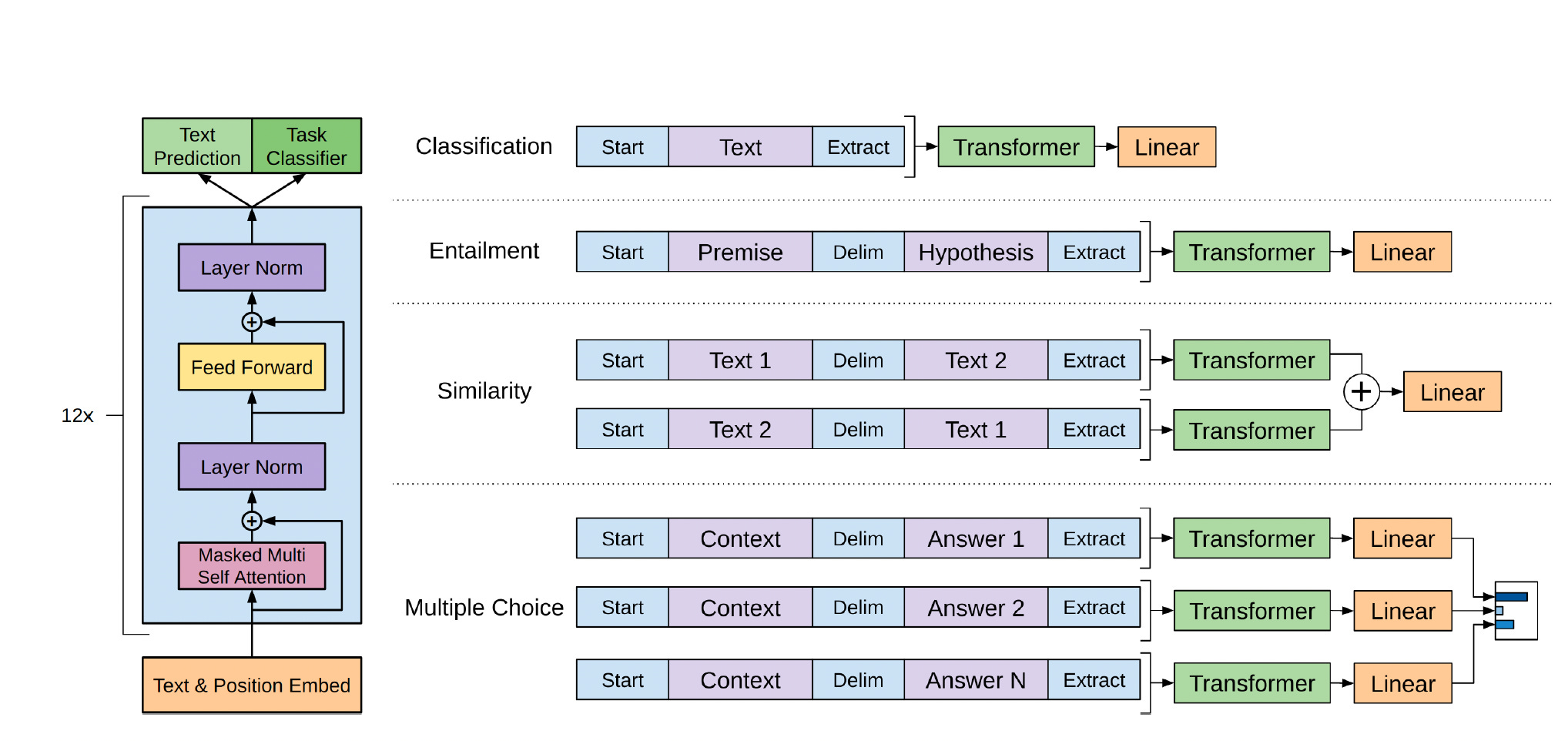
But this is only part of the solution. During pretraining, our data is a sequence of tokens: t1,t2,t3,…, where we feed the last K tokens (the context) into the attention block, and come up with a prediction for token K+1. How do we reshape our data so that it can go through this architecture and solve supervised tasks like classification, question-answering, and the like? The authors suggest one natural way to do it (right side of Figure 0).
For instance, in question-answering, the dataset consists of questions-answers couples (x-y). For each couple, we include special tokens to delimit the start and end (extract) of the couple, and a delimit token to separate the question from the answer. This sequence of tokens is then fed to the same autoregressive (one-step ahead) architecture.
Finally, we must change the loss function since we now want to model probabilities in a supervised way.
To sum up, for any SFT task (x,y) we:
Reshape the inputs and labels to fit an autoregressive structure.
Feed the inputs through the model and obtain the hidden activations from the final transformer.
Use these hidden activations to compute a linear layer:
\(P(y|x) = \text{softmax}(h^m_l W_y)\)Evaluate the loss function for the supervised task using only the labels (
y). Radford et.al. also use an augmented loss function that combines the loss functions from the supervised and semi-supervised pretrained stages. This helps the finetuned weights to not deviate too much from the pretrained weights, something that will come back when we discuss RLHF.
This idea of transfer learning is powerful, and has been instrumental for the wider use of LLMs. In “Scaling Instruction-Finetuned Language Models”, Chung, et.al. (2022) show that finetuning requires considerably lower compute (~1% of the pretraining compute resources, measured in FLOPs), that one finetuning stage can take care of multiple tasks at once, and that generalization to other tasks scales nicely with the size of the model.
Alignment: RLHF
As mentioned earlier, the focus of AI alignment is that the generated output is honest, harmless and helpful. One could in principle handle this with SFT by appropriately labeling the datasets. For instance, in a question-answering task we could in principle pass the question and answer as inputs, and a create binary label indicating if the answer was honest, harmless and helpful, as judged by human labelers:
However, it has been shown that ideas from RL can produce superior results. Recall that RL pertains to sequential decision problems, where an agent repeatedly makes a choice with the objective of maximizing the rewards from the choices. In AI and decision making I showed that LLMs can naturally be seen as “agents” that choose a word, given the state (context). Let’s formalize this a bit more.
A (stochastic) policy maps the state to a probability of taking an action. As discussed, the state corresponds to the words already seen in the context window, and the actions will now be a sequence of words. In a question-answering task, the question is the state, and the set of all possible answers (of a given length) is the action space. Moreover, for each state and action, there’s a numerical reward. Mathematically, we have two parameterized functions:5
If we knew these functions, the task for the agent is to maximize the expected rewards:
The two critical insights that will allow us to map our LLM to an RL setting are:
Next-word probabilities from the pretrained model can be viewed as stochastic policy functions:
\(\begin{eqnarray} \rho(x_0, x_1, \dots, x_n) &=& \prod_{0 \leq k < n} \rho(x_k|x_0, \dots, x_{k-1}) \\ \rho(y|x) &=& \frac{\rho(x,y)}{\rho(x)} \end{eqnarray}\)We can train a reward model using human-provided labels (feedback) as an SFT problem, using our language model as a base.
In (1) the first equation shows how the chain-rule can be used to obtain policies for actions (sequence of tokens) from the one-step ahead probabilities, and the second equation shows how we can operationalize the policy using the next step probabilities. We will use these probabilities to initialize the policy function.
The idea is now to first train the reward function, and then optimize the policy function to maximize this reward. Since we have already exerted quite a bit of effort during pretraining, we don’t want our learned policy to deviate too much from the one learned on that stage, and thus, we maximize a penalized reward function:
Training the reward function is relatively straightforward using the ideas from SFT, and reward optimization is done with Proximal Policy Optimization (PPO).
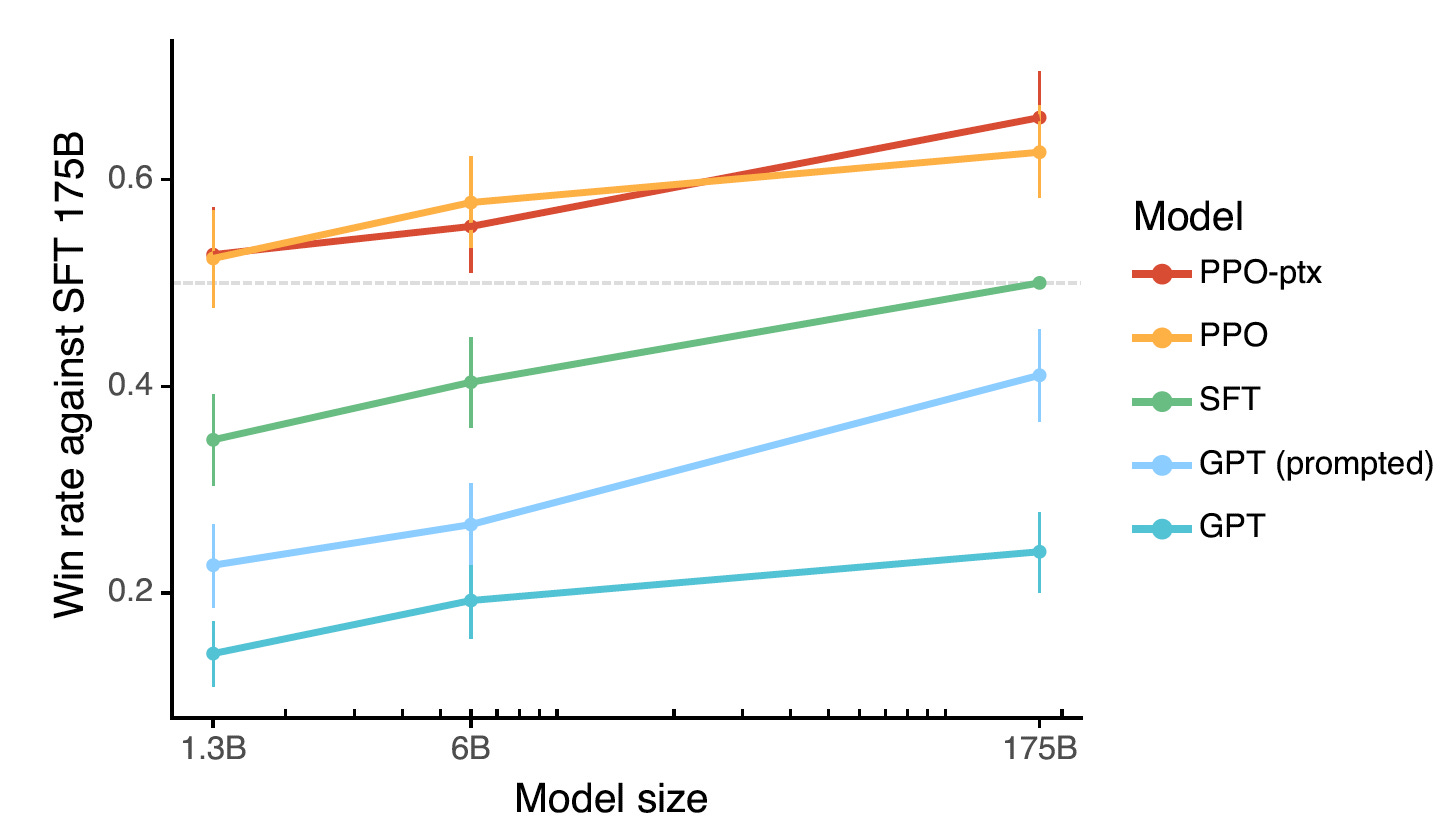
How good is RLHF? In the InstructGPT paper, (“Training language models to follow instructions with human feedback”), Ouyang, et.al. (2022) show that labelers consistently prefer the results obtained through RLHF, compared to SFT and pretrained models (Figure 1).
Why does RLHF work better?
One problem with autoregressive models is that the loss function is evaluated on a per-token basis (and later averaged across all tokens).6 But this is not how a human evaluates if an answer is honest, harmless and helpful. Put differently, predicting the next word can take us very far, but a human evaluates the ideas in a whole text, and this can be expressed in many different ways. In contrast, next-word prediction penalizes deviations from an exact phrasing.
Moreover, SFT datasets only provide a signal on the right answer, while RLHF datasets provide signals for wrong and right answers. This additional source of variation is critical for the model to learn the human preferences.
But HF is expensive
One important problem with RLHF is that creating large and rich human-labeled datasets is expensive. The Constitutional AI approach pushed forward by researchers from the AI lab Anthropic aims at solving this (and other) problem.
Suppose you start with a human-drafted set of principles that the AI should follow — called the constitution— and then generate possibly toxic prompts using an LLM. We can then use a given principle from the constitution to prompt the LLM, asking it to make a critique and amendment to the response. This process is iterated many times for any initial prompt, and many such prompts are created. Thus, we can scale the creation of datasets without human feedback. The RL stage is similar to RLHF.
The authors of the Constitutional AI paper show that it outperforms RLHF with respect to harmlessness, and is competitive with respect to helpfulness (Figure 2).

And RL is hard to implement
In “Direct Preference Optimization: Your Language Model is Secretly a Reward Model”, Rafailov, et.al. (2023) argue that we can actually skip the reward modeling and optimization steps in RLHF by viewing the LLM as a reward. Their key insight comes from their Equation (5), reproduced now:7
The ref denotes a reference policy (usually the policy derived from SFT, as in RLHF). How should we interpret this equation? The title of the paper comes from a direct interpretation of Equation (2): the LLM is itself a reward model! But if you solve for the optimal policy, you arrive at the intuitive finding that an optimal policy should assign higher probabilities to actions that are better rewarded (otherwise it can’t be optimal).
Now, suppose we’re given a prompt x and two alternative answers y1 and y2. We want to model the human labelers preferences, so one is strictly preferred to the other, or they are judged as equivalent. Since we have a reward function, we can just compute the difference in rewards from the two options (and the partition function drops out). This allows the authors to arrive at the objective function to be optimized (w and l denote the winner and loser actions in pairwise comparisons obtained from human feedback):
With this objective function, all we need to do is create a dataset of pairwise labeled comparisons (as in RLHF), and directly minimize this function. This way we circumvent the reward modeling and PPO as in RLHF. The authors show
Conclusion
Autoregressive models are powerful beasts, but can act as stochastic parrots that are neither helpful, or harmless or honest. A first approach to make them more helpful is to finetune them using a labeled dataset. This can itself take us very far. RLHF, Constitutional AI and DPO are methods to further align the models to human preferences.
ChatGPT doesn’t use the pretrained version of the model, but rather the one that has gone through the finetuning and RLHF subsequent stages.
In another blog post I will try to write about the fascinating field of mechanistic intepretability.
See Chapter 11 of Jurafsky and Martin, “Speech and Language Processing“.
You can learn how to do it in Chapter 2 of Natural Language Processing with Transformers, by Tunstall, et.al. (2022).
I’m following closely “Fine-Tuning Language Models from Human Preferences” by Ziegler, et.al. (2020).
In this section I’m following, some times closely and other times somewhat loosely, the arguments in Yoav Goldberg’s post on RLHF, which I highly recommend.
They derive this function by maximizing the penalized expected reward function, very similar to the one in Equation (1) above.
Wow, the point about RLHF not obviously fitting sequential decision-making, like you discussed in your last post, really got me thinking. Does this suggest the 'state' for LLM alignment is inherently more nebulos or continuous than in typical RL scenarios?