
Causality, Data Science and AI
Will AIs takeover causal inference?


Encoder-only large language models (LLMs), like the ones used to power ChatGPT, estimate the probability of the next word (or token) conditional on the preceding context. This structure explains why these models are called autoregressive1. Unfortunately, and somewhat misleadingly, they are also known as causal models.
In this post I will explain why the “causal” label for LLMs is misleading, make the case that causality plays a critical role for data-driven decision making, and that, at least for now, humans are best suited for this task.
Data-driven decision making
The term “data-driven decision making” has become ubiquitous among data practitioners and non-technical people alike, but it may have different meanings to different people, so I’ll start by providing the most general definition possible.
In general, a decision can be defined by:2
A set of possible actions
A reward function that assigns a reward to each action
Intrinsic uncertainty
Data can help us improve on each of these, by either filtering out the set of possible actions, calibrating reward functions and policy functions that suggest optimal or near-to-optimal actions, and circumvent the intrisinc uncertainty by providing accurate predictions to the main variables in our environment.
Suppose you want to make a reservation to have dinner tonight. The earlier you make it the better, as it will give you more options. The action space is composed by a set of possible restaurants and the default option of staying home (A,B,C, …, “home”). In principle, by use of a reward function, you will also be able to rank these options. But you may not be sure about these rankings at the time of the reservation. For instance, you might prefer something light depending on what you had earlier that day, or depending on your company, or even on weather conditions. This is the intrinsic uncertainty of the problem.
What do you need to know —what is the ideal dataset— to make the best possible decision in this example? A good trick is to always solve the problem without uncertainty first, that is, by assuming that you know everything that needs to be known for this specific problem.3 This usually sharpens your intuition, making it easier to find a better solution to the more general problem with uncertainty.
Let’s modify this problem a bit, by requiring that you want to try something new. Now you may not even know the set of restaurants!4 And even if you know them, you may not know how to evaluate them. Intuitively, the underlying uncertainty has increased, making the problem even more complex to solve.
Humans solve problems like this by using some reasonable shortcuts or heuristics. For instance, you may ask for a recommendation from people that have similar tastes. Or you may reduce the action space by filtering out options that you may think won’t work for you that day.5 These heuristics have served us well from an evolutionary perspective, but with the data scientist toolkit, and the appropriate data, it’s most likely that we can improve upon this.
This is the data-driven approach to decision making, which includes all of the necessary techniques to measure (store and retrieve) the relevant data, as well as any others that may provide useful, such as prediction and recommendation models, and the like. It’s easy to see how data science can help an organization become more data driven, if it is really willing to move in that direction.
What about causality? Up to this point the word hasn’t even been mentioned, right? The reward function has an implicit assumption that actions are directly responsible for the outcomes, in the sense that had you taken a different action the outcome would have been different. This is a common definition of causality in terms of counterfactuals.
Counterfactuals and Confounders
Let’s put this idea at work by revisiting the restaurant example. If you go to Daniel’s Pizzeria, and end up very satisfied with your meal, is it true that your going to the restaurant caused your satisfaction?
In one sense, I’d argue that this is not the case, since the quality of the food (and service) is independent of whether you go or not. In terms of counterfactuals, had you not gone to the restaurant, the quality of the food had been the same. So using this criterion, it’s not true that your going to the restaurant caused the quality, and thus, your satisfaction.
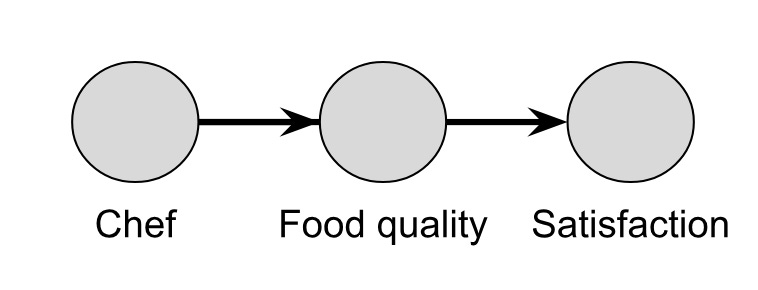
But I mentioned before that the reward function captures a causal relationship between choices and consequences. When you choose a restaurant you’re really choosing a chef (as well as their choice of ingredients, recipes and other personnel involved), and by using the counterfactual method, you can easily see that the chef does cause the quality of the food (and thus your satisfaction).
Let’s visualize this using directed acyclic graphs (DAGs), a common tool to depict relationships between variables. The DAG represents your knowledge of the problem, where nodes (denoted by circles) correspond to variables, and arrows represent if there’s a casual relationship or not. In Figure 0, the DAG shows my assumptions about what affects my satisfaction when I go to a restaurant, or what is also known as a “data-generating process” (DGP). Ideally, you and I would have the same DGP about diner satisfaction, but this need not be the case if we have different models for how satisfaction works.
What about choosing a restaurant when you’re hungry? It’s still true that your choice won’t affect the quality of the food, but it may affect your evaluation of the quality of the food. Your hunger state now becomes confounder, as it affects your choice of a chef and your evaluation of how satisfied you are after going to the restaurant.6 A DAG for this case is shown in Figure 1.
Let’s use the counterfactual method and check that your hunger state is indeed causal as the DAG represents: had you not been terribly hungry, had you chosen McDonalds, and had you felt as satisfied with the food? I can’t answer for you, but in my case the answers to both questions would show that the causal diagram is indeed a correct representation for my satisfaction.

What if you are a personality, like Barack Obama, or a social media influencer, and the chef knows that you are sitting, waiting for their food? I guess that it’s not unlikely that the chef prepares a very special meal for you (Figure 2). Imagine that Barack Obama recommends you a restaurant: if this DAG is correct, you know that the quality may not be as good as he assessed.

These DAGs are simplified representations of the causal mechanisms underlying different reward functions. The lesson is that, other than in simulated settings (like video games), it’s quite unlikely that we know the actual reward function. Rather, if we want to make better decisions, we first need to estimate it, and for this it’s critical to use causal methods.
Causality and causal tasks
A typical dictionary definition says that causality is the relationship between cause and effect. And while I don’t disagree with this definition, it feels a bit circular. To avoid this circularity, causality is most commonly defined in terms of counterfactuals: X causes Y if, had X not occurred, Y is also unlikely to have occurred.
Kiciman, et.al. (2023) describe three types of causal tasks:
Causal discovery: you want to learn how a system works. For instance, you want to learn the underlying mechanisms behind global warming. This task is commonly associated with science.
Effect inference: you want to estimate the incremental impact of doing something on a predefined metric. A/B tests operate like this, as well as the reward function discovery in the restaurant example.
Attribution: you want to “determine the cause or causes of a change”. A typical example is root cause analysis, where you try to quantify the impact of different factors on a change in an outcome metric.
In my experience, it’s quite rare for companies to care about (1), and (2) and (3) are really different faces for the same coin (incrementality).
Causality and the practice of data science
In Data Science: The Hard Parts I argue that causal inference is rather niche within the current data science practice. I also argue that causal inference is critical to create value by improving an organization’s decision-making capabilities.
Why is it niche? Using Breiman’s two cultures idea, I’d argue that the majority of current practitioners lack the statistical knowledge required for causal inference, but most importantly, are happy with the algorithmic approach and treat prediction problems as black boxes. On the other hand, causal analysis requires doing a thorough data modeling of each problem (like DAGs or DGPs) and this doesn’t scale easily.
Mature data-driven organizations can rather launch A/B tests to assess incrementality. Unfortunately, many important questions are difficult to answer with randomized experiments, and you require quite a bit of business and technical knowledge to estimate causal effects with observational data.
Causality and Reinforcement Learning (RL)
In RL, at each point in time, an agent takes an action, and gets rewarded by the environment, and the state of the world gets updated. The agent’s objective is to learn the policy function that tells her which actions to take for a given state of the world (Figure 3).

Just as with the restaurant example, it’s not obvious that the reward reflects the causal impact of the action taken, as this only happens in highly controlled environments. For this reason, Elias Barenboim and his collaborators have proposed enriching RL with methods from the causal inference toolbox.
Is GPT-4 causal?
Let’s go back to the initial claim that autoregressive models are “causal” is somewhat misleading. I’ll start by saying that the terms “autoregressive” and “causal” are used as synonyms, so really, we shouldn’t really spend too much time arguing if LLMs use causal methods in their construction: the answer is a straight no.
Interestingly, Granger causality is an approach to estimate a specific form of causality, that arose in the econometrics literature many years ago. In its simplest form, a variable X causes another variable Y, in Granger’s sense, if the past of X helps forecast Y.7 Even if only superficially, this resembles LLMs causality:
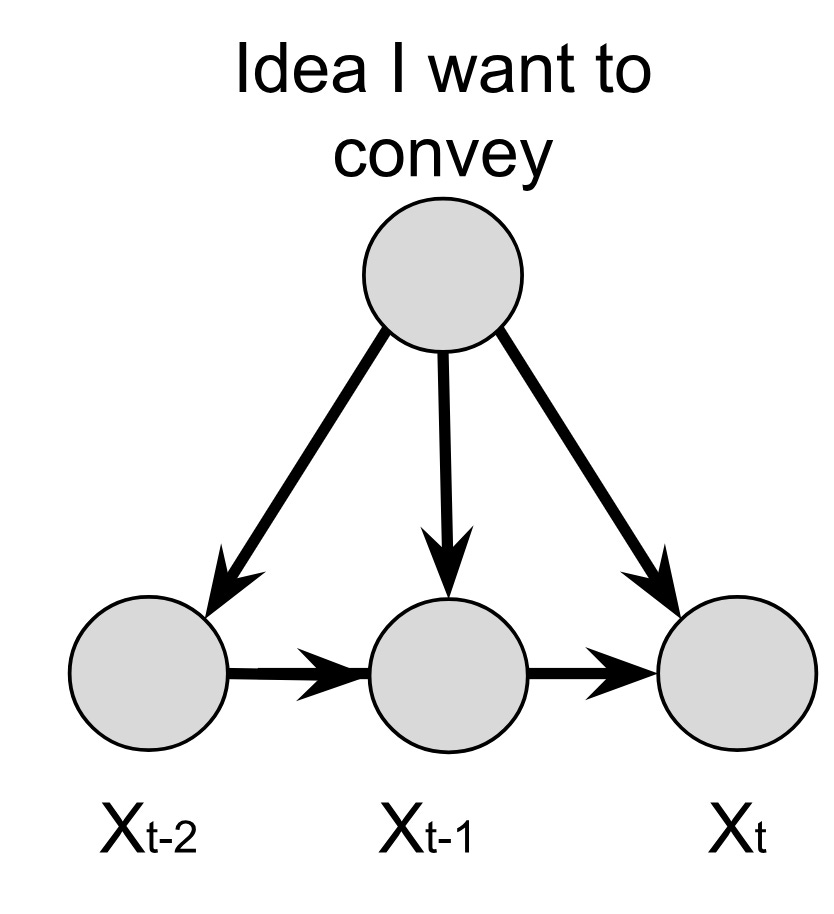
One may wonder if language is really causal, or if there’s some sort of a spurious correlation, probably because of the presence of a confounder. Figure 4 shows a DAG for one possible model for the next-word prediction model. Language is useful as long as it conveys messages or ideas, and the exact choice of words depends critically on that idea. Of course, there are rules we may want to obey to make the message as clear as possible (syntactic, social, etc.), but what ties everything together is the message. It’s in this sense that the message may act as a confounder: in its absence, the LLM may act as a stochastic parrot, as it often does when LLMs hallucinate.
Will LLMs take care of causal analysis?
The best LLMs have shown remarkable abilities in language generation, understanding, text classification, and many more, so one may wonder if they will also help us scale causal analysis.
To answer this question, it makes sense to start with the abilities that humans already have, and that have allowed us to excel at inferring causal relationships. Judea Pearl’s ladder of causation suggests that there are three levels necessary for this:
Associational: the ability to recognize patterns.
Interventional: the ability to take actions and ask ourselves if the patterns have changed or not
Counterfactual: the ability to ask ourselves if the state of the world would be different had we not performed some action.
Deep neural nets, and thus LLMs, have shown remarkable power to find hidden representations that predict patterns, so the first level has already been achieved, with remarkable success. However, at least for now, it seems that LLMs don’t have the abilities to attain levels 2 and 3. Because of the huge training data, it may appear to be so, but it’s not hard to show that most of the time it involves some type of memorization.
Two critical skills are still lacking: having an understanding of how the world works and planning.8 Nonetheless, some authors have started to explore the use of LLMs as assistants or copilots and traditional causal inference. As Kiciman, et.al. (2023) say:
We envision LLMs to be used alongside existing causal methods, as a proxy for human domain knowledge and to reduce human effort in setting up a causal analysis, one of the biggest impediments to the widespread adoption of causal methods.
How can this work? In a typical A/B test design you start with a set of hypotheses. Thanks to the amount of memorized knowledge that the LLM has, it can be used as a copilot to ideate these hypotheses. Similarly, one can use an LLM to augment or restrict a given DAG or DGP that we’re working with.
Final words
If models keep increasing in size (parameters and corpus), will they become proficient in performing causal analysis? To be honest, it’s hard to know, though I think it’s unlikely. We need to create models that “understand how the world works”, and current LLMs seem to be far from doing so.
At this point it seems that humans have a comparative advantage on this, but data scientists may need to augment their toolbox with methods from causal inference, especially since LLMs are becoming better at tasks that may become automated in the future.
If you’re familiar with autoregressive time series models you’ll immediately find the similarity.
You can find a thorough description of decision problems in Chapter 2 of Analytical Skills for AI and Data Science: Building Skills for an AI-Driven Enterprise.
See Chapter 6 of Analytical Skills.
I discuss DAGs, counterfactuals and confounders at length in Chapter 15 of Data Science: The Hard Parts.
I’m being quite loose here: in practice you evaluate the MSE from the forecasts of two different models, one that uses the past of Y and other relevant variables denoted by W, and one that augments this model by also including lagged observations of X. The MSE from the latter is lower then you have Granger causality. In practice people test for the statistical significance of the coefficients for the lags of X.