
Understanding Emergent Capabilities in LLMs


TL;DR
In this post, I discuss the problem of “emergent” capabilities in large language models (LLMs). The discussion is motivated by a recent paper that presents a model to explain the phenomenon of the emergence of skills in LLMs. I start by defining emergence as the appearance of skills in larger models that were not present in smaller models, and that couldn’t have been predicted from model size growth. I then discuss the main result of the paper, that shows that new language tasks can be successfully tackled by a combination of skills that arise naturally as models grow in size. Finally, I discuss another recent paper that argues that emergence may not be real, but rather it could be an artifact of the grading measures used by researchers.
Introduction
The rate of improvement of large language models (LLMs) has stunned everyone, from hard-core believers to many of the skeptics of the impact of Generative AI (GenAI). Nonetheless, there is still substantial disagreement about whether LLMs actually understand the underlying concepts, and are able to build a model of the world used to assess specific tasks. Furthermore, even if there’s some level of understanding, we know little about how it happens.1
I recently came across an article in Quanta Magazine that describes the results of a paper published on ArXiv in November of 2023. The paper, coauthored by Sanjeev Arora (Princeton) and Anirudh Goyal (Google DeepMind), presents a mathematical theory for how different skills emerge as models grow in size. In this post I want to discuss the main result of the paper, as well as some other relevant background information about the topic.
Emergent capabilities and scaling laws
In a previous post I proposed four general principles underlying GenAI (Figure 0). Anyone who has used ChatGPT or Bard can attest that these technologies are great at retrieving information, and at generating and understanding language. Truth be told, when they don’t know something, or the phrasing of the prompt is not clear enough, they can sometimes hallucinate, thereby providing incorrect answers.

Moreover, LLMs appear to be governed by scaling laws, whereby increasing the size of the training set (D) and the size of the model (N) reduces the loss on the test set in a remarkably predictable way:2

As models have continued to grow, not only are they becoming more predictive, in the sense of lowering the test loss, but the scope and generality of what they can do has also continued to expand. For instance, models that are trained to predict the next word, are not only able to generate text at a human level, but also excel at translating across languages and coding tasks (machine translation), sentiment analysis (text classification), identifying entities (named entity recognition), just to mention a few of the most common tasks in the field natural language processing. Before the advent of GenAI, different models had to be developed for each of these tasks.
Moreover, LLMs have already achieved human-level skills at many standardized tests, and there are now a plethora of benchmarks used to evaluate the improvements at tasks that include math, logical and common sense reasoning, and many others. Similarly, new techniques such as chain-of-thought, and zero- or few-shot learning are commonly used to reduce hallucinations when prompting an LLM about topics that are not in the training set.
Emergent abilities can be defined as “abilities that are not present in smaller-scale models but are present in large-scale models; thus they cannot be predicted by simply extrapolating the performance improvements on smaller-scale models.”3 Some examples are presented in Figure 2.

What skeptics say
Despite these advances, some researchers still think that LLMs are no different from stochastic parrots, that memorize their training data, and hallucinate when forced to produce some output not present therein. Moreover, it has been established that there’s training data contamination, which may explain why LLMs fare so well at many standardized tests.
Other researchers have shown that LLMs lack planning abilities, and the now infamous Q-star incident with OpenAI is reminiscent of the current understanding that planning is a critical skill to achieve human level intelligence.
A related point is whether LLMs have a “world model”. For instance, Yann LeCun is quite skeptical about autoregressive language models having an underlying model of how the world works, and has even proposed a different architecture that could lead to human-like reasoning skills.
How can new skills emerge?
In “A Theory for Emergence of Complex Skills in Language Models”, Arora and Goyal develop a mathematical model with the following building blocks:
Scaling laws: they assume that the cross-entropy loss exhibits a power-law scaling law (see Figure 1 above)
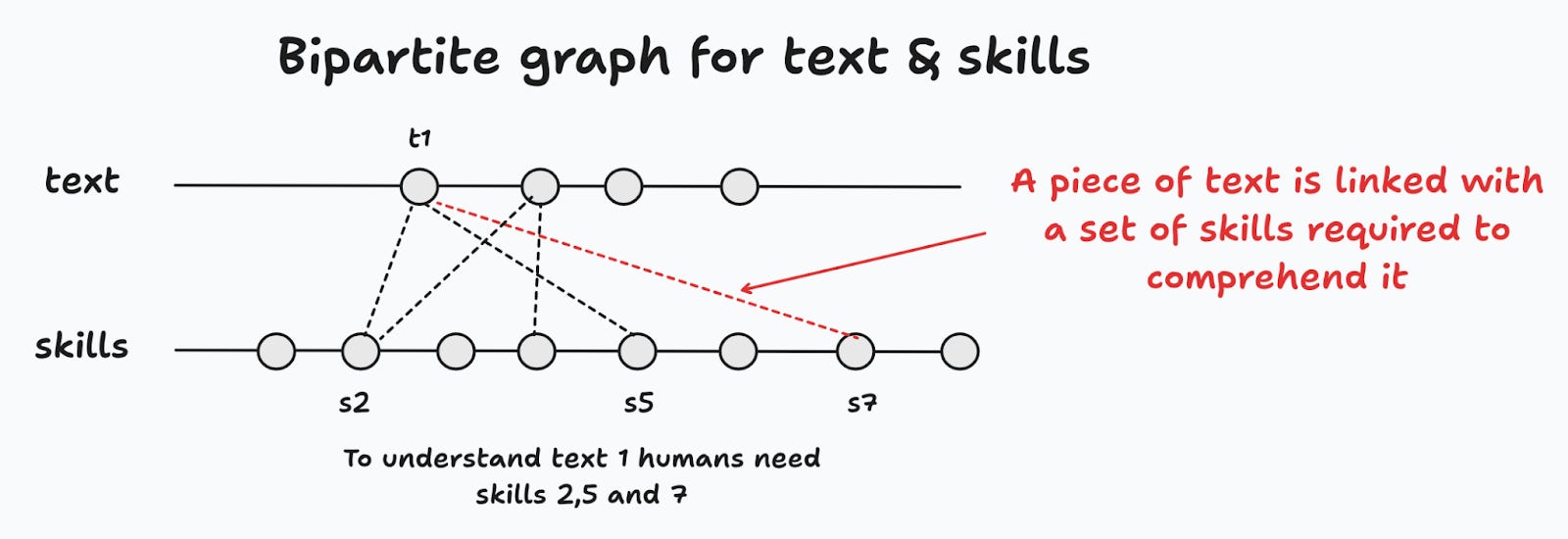
Bipartite random graph: skills and text are arranged in a random bipartite graph (Figure 3). Every piece of text in a corpus (sentence, paragraph or larger) is linked to different skills. A link between
(t,s)is interpreted as “skillsis needed to understand textt”. The graph is a collection of text, skills and the links, and links are assumed to be generated randomly (but once assigned by nature the edges don’t change).Skill competence: We can measure “competence” in each skill by way of multiple-choice “cloze” questions.
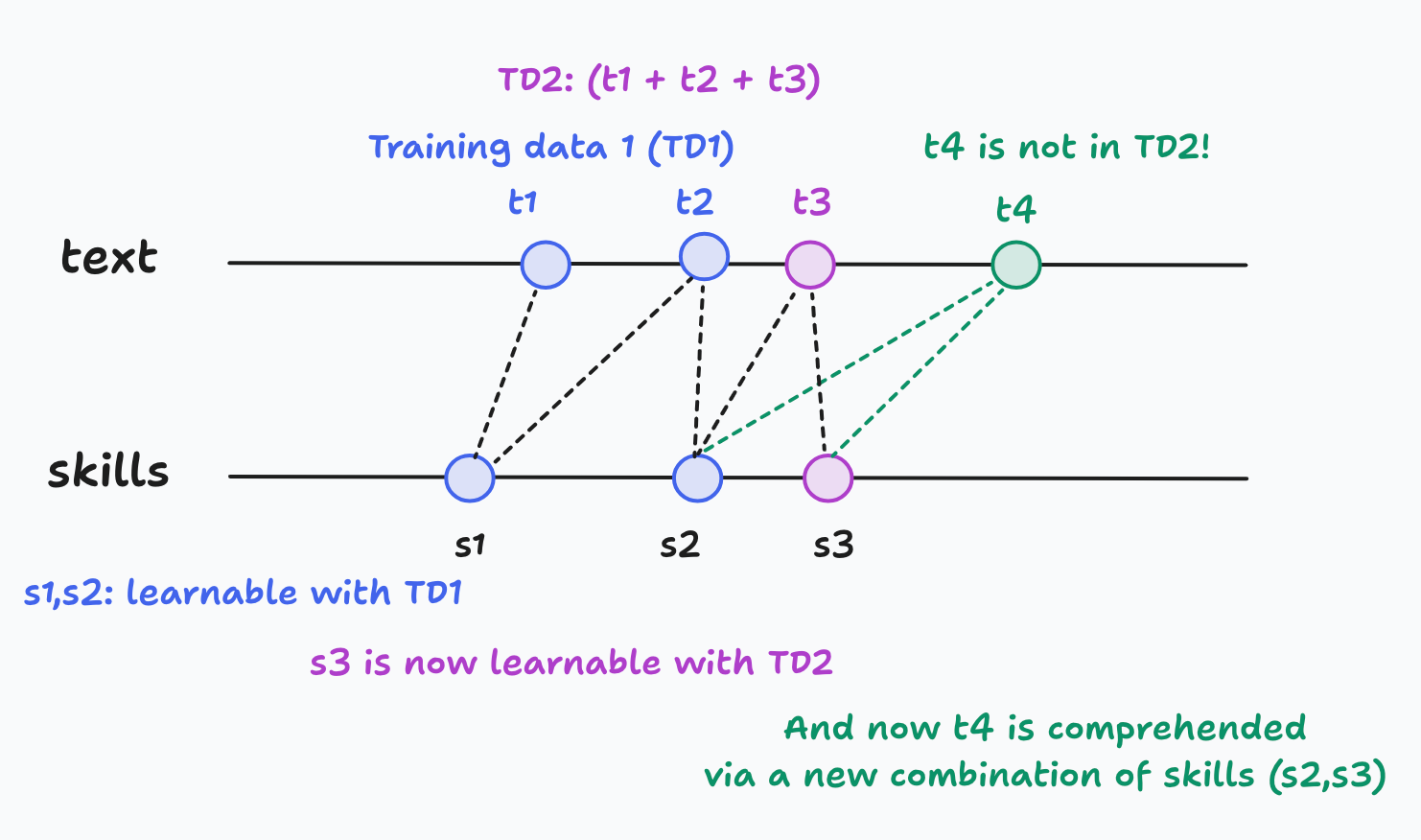
The main result is that as models grow, new skills are learned, and these new skills combine with previously learned skills so that new text pieces can now be comprehended (Figure 4). Note the importance that the quality of the corpus has: if you include redundant corpus (not necessarily identical copies), the model size increases, but no new skills can be learned.
Are emergent skills a “mirage”?
One of the papers that won the Outstanding Main Track Papers at the most recent NeurIPS 2023, tackles the problem of emergence from a different perspective. In “Are Emergent Abilities of Large Language Models a Mirage?”, Schaeffer, et.al. (2023) argue that abilities may not really “emerge”, but rather appear to do so because of the discontinuity of the metrics used in the evaluation. One example of such a metric, provided by the authors, is a multiple choice grade such as:
The authors then show that, for InstructGPT/GPT-3 and a specific set of arithmetic tasks (addition and multiplication of digits), by changing the evaluation metric from a discontinuous to continuous one, the performance of the models improves smoothly, instead of showing a sharp discontinuous jump as the “emergence” definition expects.
Note that the authors admit that this does not imply that LLMs can’t display emergence, but rather that current emergent claims may be an artifact of the performance metrics used.
What next?
The two papers discussed could both be correct: it may very well be that the sharp discontinuity is a byproduct of the evaluation metrics used, but it may also be true that larger, and more diverse, training data sets, allow LLMs to learn new skills, or at least appear to do so. As a matter of fact, both results make intuitive sense.
The question of whether the models genuinely learn new models of how the world works is going to remain in the public’s attention for a while. And at least to some degree, the answer doesn’t really matter. Much progress can still be made, even if the models are just mimicking to learn something. To be honest, the question matters most for those seeking to create Artificial General Intelligence (AGI). But we don’t need to get there for GenAI to have a substantial societal impact.
For instance, you can check the conversation between two of the most notable figures in the field, Geoffrey Hinton and Andrew NG.
Several papers discuss scaling laws for LLMs. See, for instance, Scaling Laws for Neural Language Models.
Quote taken from “Emergent Abilities of Large Language Models”.