


Patterns of adoption of GenAI
Or how to navigate uncertain times and not lose your mind


TL;DR
The struggle is real: many companies are trying to figure out the best way to implement a successful GenAI strategy.
Three-ish patterns: there are three patterns of GenAI adoption: general adoption via chat interfaces, simple deterministic workflows, and agentic workflows. There’s also a parallel track of software engineering productivity, that lies closer to the chat interface.
General tier: the chat stage is aimed at improving general productivity, but gains may not be substantial enough to make them measurable.
Deterministic tier and developers: simple deterministic workflows are built within current operational processes. Value comes from cutting costs that generate localized productivity gains.
Agentic workflows and AI engineers: AI engineers build agentic workflows, characterized by being probabilistic in nature. There are reasons to believe that gains will be substantial, but at this point the confidence intervals are also large.
Fine-tuning: model fine-tuning has lost momentum, but this might change in the near future if some key technical challenges are overcome.
Data orgs: GenAI lives naturally within the more general ML+Data org. Success requires a centralized strategy, but decentralized execution. AI engineers should work closely with product, tech and data scientists.
It’s never too early to think about strategy
ChatGPT was released in November 2022, and things have been wild and crazy ever since. GenAI dominates public attention, adoption rates have skyrocketed,1 and companies are struggling to get a hold of how to navigate the hype, trying to separate signal from noise, while ensuring that they won’t lag behind their competitors.
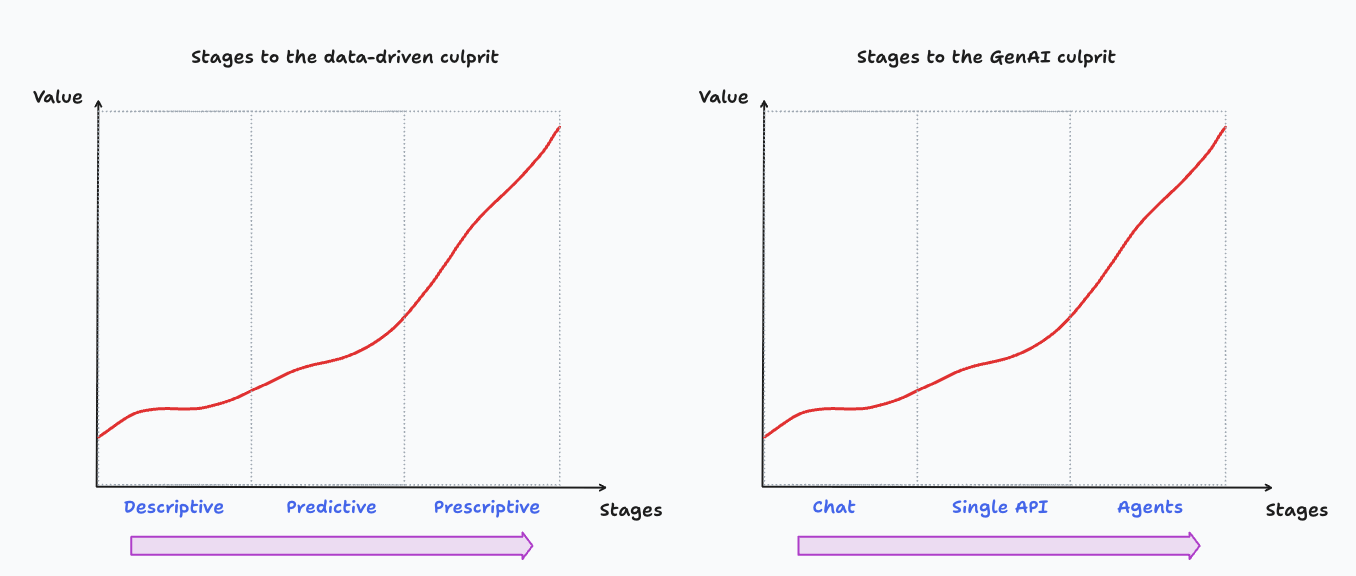
Not so long ago, the industry went through a similar hype cycle with the data-driven revolution (DDR) . In this post I’ll describe different patterns of adoption of GenAI, and draw some parallels with the DDR transformation.
Before taking off, a word of caution is in place: it’s still very early to understand where the AI transformation is taking us, so many things can change very soon. Nonetheless, I’m convinced that inaction is not an option, and companies need to be able to navigate these uncertain times. Also, the DDR transformation is far from over, and for many companies it has failed to deliver the promises. At this point, it’s good to be cautiously optimistic about the potential for GenAI.
Maturity stages
The next figure shows maturity stages for DDR and GenAI.2 Companies tend to move sequentially through stages (from left to right), but in practice, adoption is rarely this ordered, and at any given point in time, organizations have concurrent projects across the different stages.
On the vertical axis we have value, better understood as potential in nature; how much a company realizes depends on how well they’re able to make the required internal technical, organizational and cultural changes.3
The Chat stage
The first stage in the GenAI transformation is the Chat phase. This is how most of us use GenAI on a day-to-day basis, by interacting with an LLM via ChatGPT, Claude, Gemini, LeChat, or the like. It has a friendly user interface, and desktop and mobile access is commonplace. Multimodality is also a feature, so you can easily share pictures or documents, and directly talk to the model.
Data privacy is a big concern for companies, so two patterns have arisen: enter into an enterprise contract with data security guarantees, or outrightly block all access. The first pattern is often preferred, and IT budgets now have the corresponding GenAI accounts. Companies like Google or Microsoft have also bundled GenAI services into their enterprise offerings, so many companies can actually get the benefit from these services at no incremental cost.
This is a general-access tier aimed at improving productivity across the whole organization. Typical use cases are ideation, content and document creation and research, tools that are now widely available via the chat interface. While most of us would agree that GenAI has made us more productive, it’s unlikely that this stage will generate significant and measurable gains.
The chat stage creates some productivity improvements, but the impact is low and hard to measure.
An alternative pattern of general consumption of GenAI comes from third party solutions embedded in SaaS offerings.
Single API call and simple deterministic workflows
The next stage is characterized by embedding GenAI into the existing product and operations processes. Automatization is achieved by creating simple workflows that combine single API calls to large language models (LLM).
This stage has three characteristics:
Programmatic: requires programmatic access, as opposed to the general chat interface
Developer-driven: because of this, the driver of the change is the individual software developer that connects to an API.
Deterministic workflows but probabilistic outcomes: the nature of the workflows is highly controlled and deterministic, meaning that the developer knows exactly how it starts and how it ends. Nonetheless, LLMs are probabilistic by design, so different testing and evaluation frameworks are required.
Incrementality is more readily measurable, and value comes from reducing costs. Programmatic access to LLMs generate additional risks, forcing organizations to put in place stronger governance processes and guardrails to ensure the smooth continuity of the business.
Companies that don’t have a strong software development capability can still benefit by integrating third party SaaS solutions into their IT stack, but this naturally comes with a lag, and without creating long-lasting internal capabilities.
The second stage requires programmatic access to LLMs where the output from a model is embedded into production processes. Proximity creates a measurable upside, and risks that organizations may not be prepared to control.
Agentic workflows
The third stage consists of building complex workflows that are operated and orchestrated by the LLMs themselves.4. Once LLMs take over control, the workflows themselves become probabilistic too, as opposed to those in the second stage.
The ecosystem has grown rapidly this year, and adopting a common standard (e.g. model context protocol, or MCP) should accelerate it even more. The whole idea is that LLMs with access to better context and more tools are able to accomplish more tasks independently. This naturally expands the set of possible use cases, with a corresponding expansion of the value frontier.
The main driver is no longer the single developer, but rather the new role of AI engineer which I describe more fully below. Higher returns come with substantially higher risks, further straining the governance capabilities for the company. All this is still in the making, and we should expect a lot of internal experimentation as well as a dynamic third party governance and security ecosystem.
Parallel track: improved developers productivity
A parallel track for value creation is achieved by improving the productivity of software developers internally, meaning that Tech can now ship more and better software with the same resources.
This is somewhat of a low-hanging fruit for tech-driven companies with strong development practices, and it resembles the chat stage. There are two differences, however:
AI labs are working hard to make LLMs better at coding.
It’s easier to measure the impact on developers’ productivity.
As LLMs become better at generating code, a low-hanging fruit to create value is by making developers more productive.
Adopt vs. create
Each stage requires someone in the organization to take action. The chat stage requires each employee to adopt the new tools created by GenAI, and to some extent to reinvent the way they work. A centralized training and communication strategy can help, but it may also require strong leadership and aligning incentives to specific milestones.
The same thing can be said about the developer’s track, but here I’d reinforce the leadership requirement: I’ve seen teams of developers with almost zero adoption of something like a “basic pack” of IDE + Github Copilot because of a lack of leadership. Another thing that works is having team or squat champions or evangelists, whose main role is to constantly test new technologies and share the insights within and across teams. In my opinion, developers are as confused as the rest of the organization, and it may require substantial individual and organizational efforts.
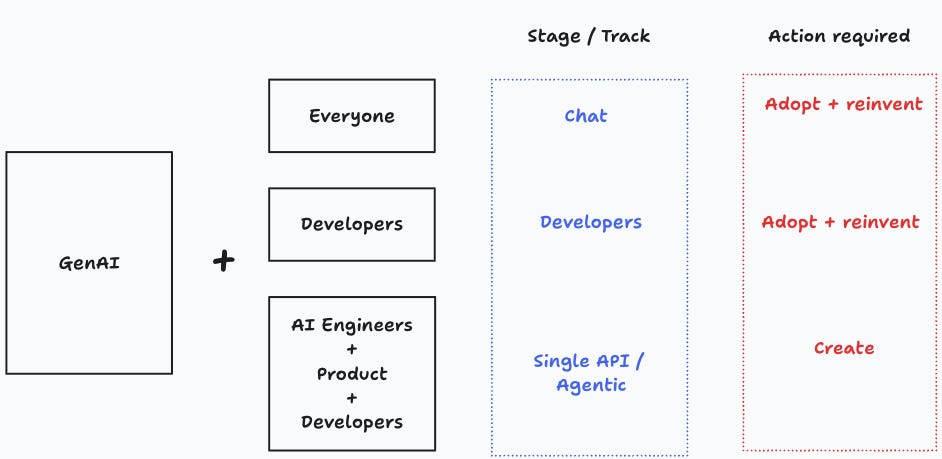
The second and third stages are somewhat different in that more than adoption these require creating new systems or augmenting the existing ones with GenAI functionality. At a minimum, the second stage requires learning to do some prompt engineering, and the third stage requires some considerable skill augmentation and retraining.
Many people in the organization are confused, developers included. Communication and setting up expectations, as well as aligning behavior to these expectations are important organizational levers.
The new role of the AI engineer
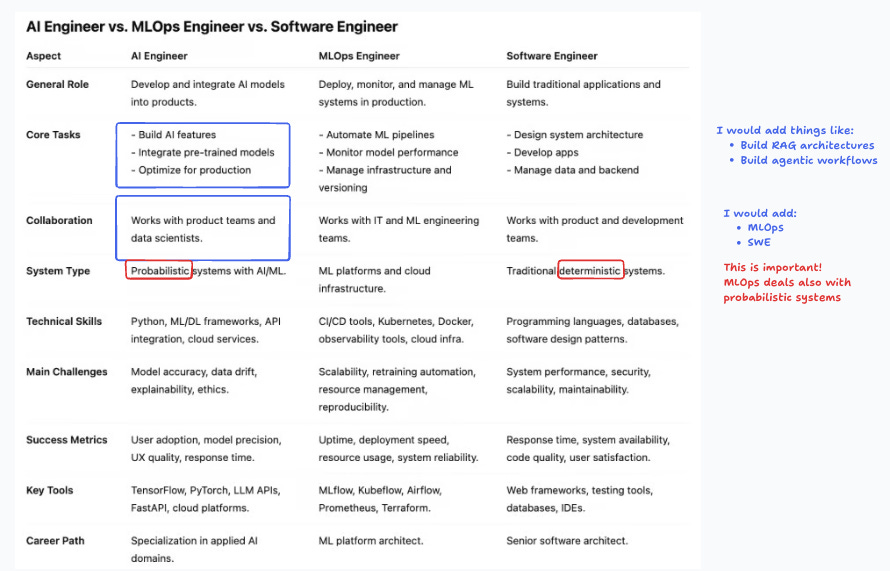
The GenAI transformation has already created one short-lived role, and another that appears to be more enduring. Not so long ago, everyone was talking about the rise of the prompt engineer.5 Nowadays people talk about the critical role of AI engineers.
The AI engineer is somewhat special, and still mysterious to many, especially for those in the software development realm. I asked ChatGPT to compare the three roles, and the table below summarizes the results.
The main difference is that AI and MLOps engineers both deal with probabilistic systems, as opposed to the traditional deterministic systems that software developers design and operate.6 This creates a whole new set of challenges for the organization, like how to evaluate performance, or how to avoid errors that compound in agentic workflows.
Most companies are still transitioning through the first two stages, so the demand for AI engineers is still sluggish, but in the near future this could change drastically.
Successful AI engineers embed probabilistic systems into operational processes. This requires working hand-in-hand with MLOps, data scientists, software engineers and product teams.
To fine-tune or not, that’s the question
Current models are very general, and can be used for anything from summarization, ideation, content creation, writing novels and poetry, as well as for building specialized agentic workflows. This generality has worked great to accelerate adoption, but agentic processes may require more specialization.
Fine-tuning models with the company’s own data can provide these specialized models, and two paradigms have been explored: supervised fine-tuning and reinforcement fine-tuning. Unfortunately, most companies lack the technical know-how to execute this successfully. Moreover, problems like catastrophic forgetting are real and there’s still no consensus on what to do about it.
At this point fine-tuning is not an option for the vast majority of companies, and agentic workflows with access to RAG-like architectures and better memory management can provide enough specialization. Nonetheless, it’s quite likely that in the short- to medium-terms there will be access to smaller models that allow for more specialization.7
Fine-tuning is not yet a reality for the vast majority of companies, but it’s something that could happen in the near future.
Org structures
Most companies were still strengthening DDR capabilities internally when the GenAI transformation came with full force, creating organizational confusion and frustration.
A typical and natural solution is to augment the data org with the new responsibilities. This makes sense since, under the hood, transformer models are already part of the machine learning toolkit. To be sure, building LLMs requires highly specialized technical expertise that only large AI labs can afford, but ML organizations are, at the very least, literate enough to understand how LLMs work, and can therefore execute the crucial last-mile.
This said, the reality is that GenAI efforts many times end up assigned to Tech or IT, that lack the proper understanding of the technology and its capabilities, resulting in frustration and adoption lags.
Ideally, GenAI should be led by a C-level AI executive responsible for everything data + ML related.
As with DDR, GenAI strategy is better conceptualized by a centralized vision, decentralized execution mantra. This means that AI engineers and data scientists should be embedded in teams with product and tech for successful implementation.
What’s next
With respect to GenAI adoption, literally everything is “next”. We’re all learning how to do this in real-time, and the struggle is real. It’s better to avoid over-strategizing, and even better if you actually start building things. Compared to DDR, barriers to entry in GenAI are substantially lower.
Is your organization doing something else? Please share this in the comments.
According to one researcher, in June 2025 almost half of the US labor force report using GenAI at work. Another study from 2024 found that adoption is highest in occupations that are most exposed. In February 2025, ChatGPT reached 400 million weekly active users.
I’m not fond of using maturity stages unless it’s really emphasized that this is only a metaphor for how things could unravel.
For the case of DDR, I recently discussed the type of organizational changes that need to happen to realize more of this potential value.
Many people have different definitions for agents and agentic. I’ve found Anthropic’s approach to building agentic workflows most useful.
Newer models require less prompting effort so the role is no longer relevant. This is not to say that prompting is not important: it remains a critical skill in the AI engineer toolbox.
Systems that use any machine learning model — LLMs included — are probabilistic in the sense that for a given set of inputs