


Data-drivenness in the age of GenAI
Or how robots won't take over this part of the data science workflow, at least for now.

I recently gave a talk with my reflections about the impact that GenAI is having on the way we make better decisions with data. This post gives an expanded view.

TL;DR
People and machines are data-driven, not just in the way data practitioners use the term.
What practitioners mean is consistently acting upon evidence.
Evidence is opinionated, data is a passive observer.
The business case for data-drivenness is positive whenever there’s uncertainty.
Uncertainty hasn’t fallen in the age of GenAI: the cost of acquiring information has fallen, but hallucination rates undermine part of the gains.
Uncertainty falls when new world models are discovered: the current generation of models appear to lack these world models (and the capability of generating such models).
The relative value of having analytical skills will only go up with GenAI, and learning the evidence-based approach still makes sense.
Are you data-driven?
Ask this question to your audience (your partner, your team, etc.) and almost invariably you’ll get the same answer. Most of us believe we are data-driven, and in a very real way, this is true. Our brains are powerful predictive machines that evolved to find patterns in the world and make better decisions because of it. So yes, we are data-driven creatures.
Whether you use Excel or a non-relational database in the cloud to store your data doesn’t make you more or less data-driven. Even the infamous highest paid person (HiPPO) is data-driven.1 And a large language model (LLM) that powers GenAI is data-driven too.
But here’s the thing: when data practitioners refer to data-drivenness, we mean something profoundly different.
Most of us believe we are data-driven. And we are. Just not in the way data practitioners use the term.
Data-drivenness before GenAI
I asked Claude to compare the mindsets of the data scientist and of the hypothetical HiPPO, and this is what I got:
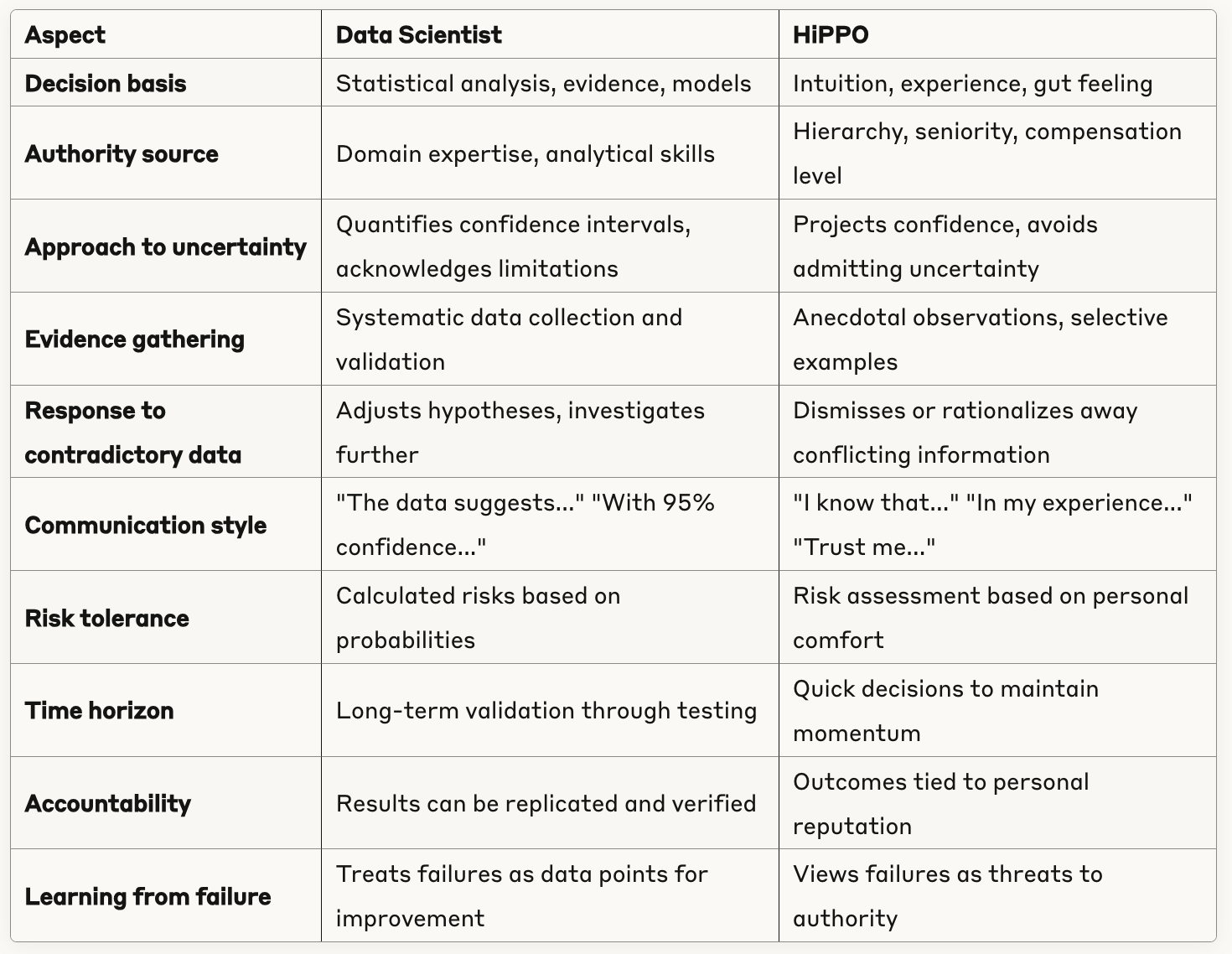
I may disagree with some specific aspects of Claude’s answer, but overall I think it captures very accurately several traits of data-drivenness which can be summarized as: to be data-driven you need to consistently act upon evidence.
The defining feature about being data-driven is the ability to consistently act upon evidence.
In the following chart I highlight some of the key traits underlying the evidence-based approach.
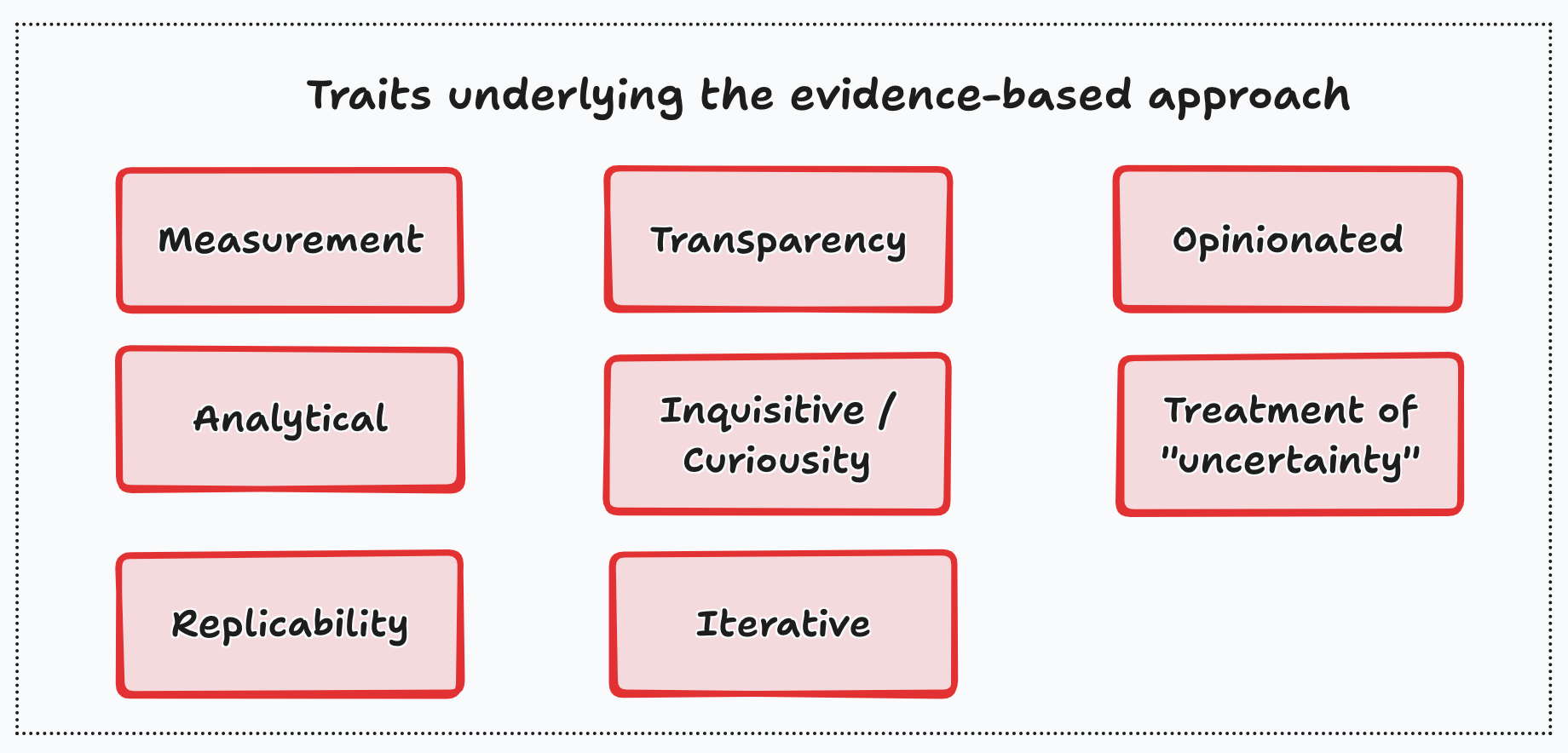
Many organizations believe that to be data-driven you need to have the data first, and that having more (and more varied) data, the better. I actually think that the “data piece” is actually the “easy” part of being data-driven.2 You first need to have well-defined metrics, a thorough and analytical understanding of the business, and some critical cultural traits that ensure the acting upon evidence can be made consistently.
Having data is the easy part of being data-driven.
Data vs. evidence
It’s important to understand the difference between data and evidence. As the following definition states, evidence is data that allows one to form an informed opinion about the validity of a hypothesis. So all evidence is data, but not all data is evidence. Evidence is opinionated, while data is rather passive. These opinions tend to come in the form of hypotheses; hypotheses around uncertain phenomena that we try to simplify and model.
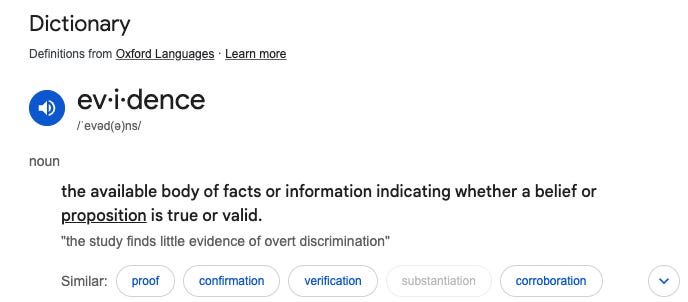
Evidence is opinionated, data is a passive observer.
Consistency
Consistency is a somewhat implicit part of the definition of data-drivenness. To be sure, one-shots are better than nothing, but to really capture the value from evidence-based business making it’s important to make it a deeply ingrained value in the organization.
This is what data-drivenness entailed before GenAI, and a very large managerial literature emerged suggesting “best practices” to achieve this organizational transformation. I won’t review that literature right now; I’ll just say that becoming data-driven is very hard precisely because of these other traits. Again, data is the easy part of being data-driven.
What is the value of data-drivenness?
The evidence-based approach only makes sense in a world with uncertainty. The idea being that we need to learn how the world (our businesses, our customers, our employees, our processes, etc.) works, and the fastest way to do it is by formulating hypotheses and subjecting them to systematic tests.
In Analytical Skills for AI and Data Science I argue that the main sources of uncertainty that matter for a business are ignorance, emergent behavior from complex phenomena, social interactions (and the peculiarities that arise with human behavior), heterogeneity and our need to simplify the world. The data-driven toolkit allows us to approach each of these, one at a time.
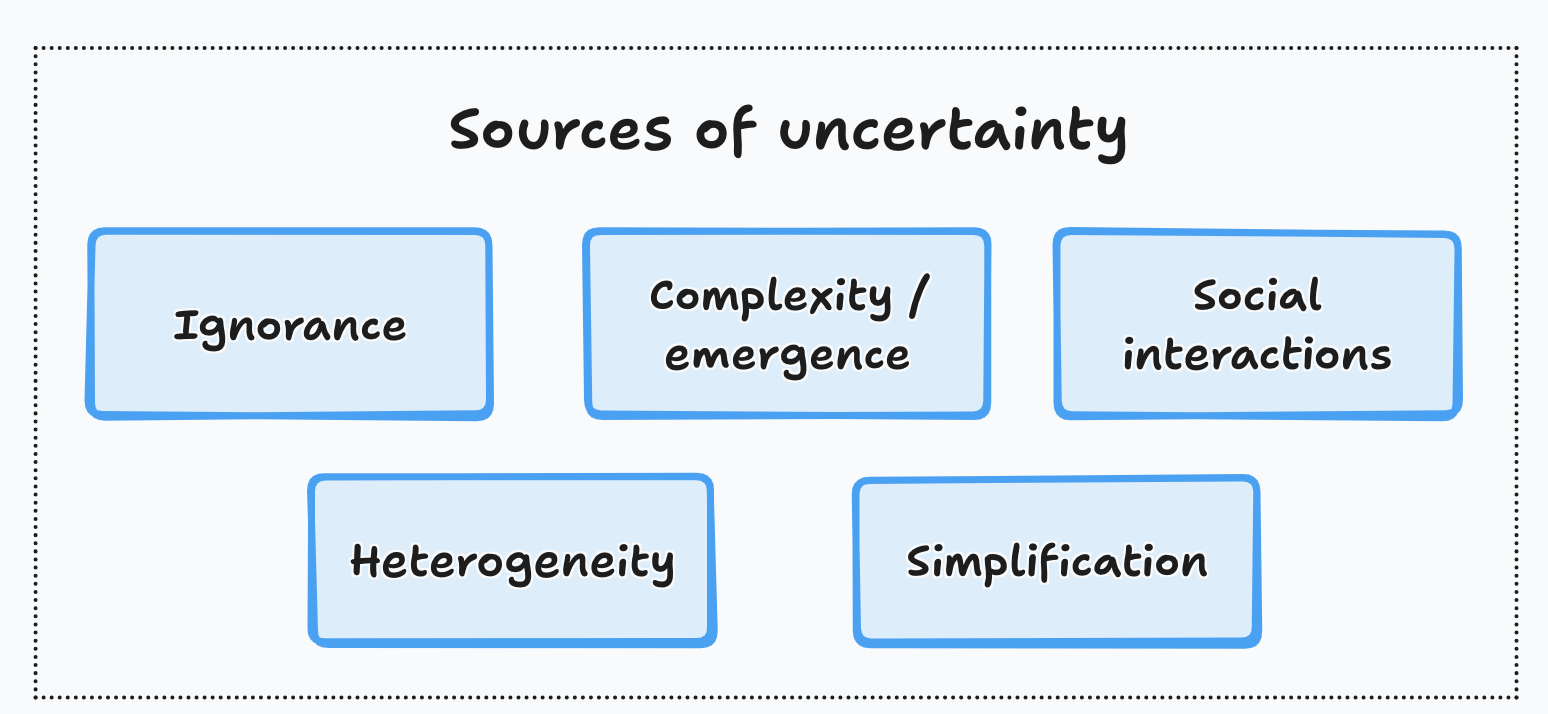
The business case for data-drivenness is positive only when there is uncertainty.
Data-drivenness in the age of GenAI
So has anything changed with the development of GenAI? Is being data-driven still valuable in this age of intelligent machines, and the likely prospects of AGI or ASI?3 Also, is AI making it easier for companies to become data-driven?
Has the value of data-drivenness fallen because of the rise of GenAI?
The value of data-drivenness will only fall if the “world” becomes more certain thanks to the rise of AI. I will argue first that while the cost of acquiring information has lowered, uncertainty has not fallen, and thus, the business case for data-drivenness remains as positive as ever.
Uncertainty in the age of GenAI has not fallen, so being data-driven is as valuable as ever.
As I wrote almost a year and a half ago, GenAI is better understood in terms of its most basic capabilities, one of them being information retrieval. This just means that we can now get answers to most questions any human might ever have, and many times the AI has the right answer. In some real sense, that information that is at our disposal reduces the uncertainty coming from individual ignorance.4
For instance, with LLMs you no longer need to have a Ph.D. in economics to come up with a sophisticated pricing strategy; someone may have already done this, and the LLM will tell us. And this collective knowledge may reduce our need to test, lowering the value of the evidence-based approach.
Naturally, this is true if the LLM does not hallucinate. I presume that hallucination rates are lower for problems that are better known, and are further explored in the training data, so that the marginal impact may be small for these “easier” problems. The harder problems, those that are still in the “knowledge frontier”, will have very high hallucination rates. And I’m not talking about quantum entanglement here. I’m thinking things that are rather mundane and down-to-earth, like what si the next best offer for your customer.
Hallucination rates are a new source of uncertainty that limit the impact of GenAI.
To summarize, while it’s certainly true that GenAI has lowered the cost of acquiring information, it’s far from obvious that the current state of LLMs will have a significant impact on our underlying uncertainty. My bet is that the data-driven approach is still as valuable as before.
Will GenAI improve our understanding of the world?
When Einstein came up with the theory of general relativity, he lowered our uncertainty about how the universe works. In general, lowering our societal ignorance about how the world works has that effect.
It’s not the case yet, but in a foreseeable future AI may have accurate enough “world models”.5 When that happens, the value of the evidence-based approach will indeed lower, but the other sources of uncertainty will remain.
It is now possible to envision a future where evidence-based and superintelligent AIs will discover new world models. Since this is a world with uncertainty, even then, the evidence-based approach will be valuable for these machines.
What about a colony of emotionless AIs?
As behavioral economics has shown, significant consistent departures of the rational ideal come from cognitive biases. It could then be that delegating part of our decision-making process to AI can improve the outcomes.
While this doesn’t lower the value of the evidence-based approach, this might be an interesting side effect to explore. One common use case for AI is helping to craft emotionally intelligent responses. Alternatively, an egoless decision-maker, even if it doesn’t have better world models than humans, could generate incremental value.

Analytical skills will be on high demand
A completely different view is that current LLMs will be able to automate repetitive tasks, increasing the relative value of our unique analytical skills. In this scenario, the age of GenAI might actually increase the demand for data-driven employees.
AI may help with the collection of data, and the like, but the hard work of framing a business problem, understanding the key metrics, coming up with hypotheses that make sense, and iterating once we have new evidence, seems to be, at least for now, a task where humans are best suited.
To sum up
Being data-driven is as valuable in the age of GenAI as it was before, the reason being that as long as there’s uncertainty, the business case for evidence-based business-making remains positive. GenAI will make the process of automating data collection, monitoring and governance easier, but consumption still requires a powerful analytical skillset.
The highest paid person opinion, or HiPPO, is a useful metaphor used to represent the antithesis of what we want a data-driven decision-maker to be.
To be sure, getting the right data is not that easy, but that’s the subject of my next post.
AGI refers to artificial general intelligence (i.e. machines that can do what humans do) and ASI to artificial superintelligence (or the case of machines that can quickly update themselves to become far superior to humans).
In “Superintelligence: Paths, Dangers, Strategies”, Nick Bolstrom argues that one path to ASI is what he calls “collective superintelligence”, that is, one the aggregation of individual “smaller intellects” generates a powerful aggregate. I’m not claiming that current GenAI achieves this, but by aggregating the knowledge of the internet, something similar may be in the workings.
For instance, people like Yann Lecun believe that LLMs don’t have world models, and that it’s unlikely that they will ever have one.