
Probabilistic and Deterministic Systems
How AI is different from traditional software development


TL;DR
GenAI systems are probabilistic, not deterministic - Unlike traditional software that produces predictable outputs, AI systems inherit uncertainty and require fundamentally different approaches to building and testing.
Traditional unit testing doesn't work for AI applications - Probabilistic systems need evaluation frameworks (evals) with datasets, metrics, and repeated measurements rather than simple pass/fail tests.
Developers need new skills beyond basic prompting - Successfully implementing GenAI requires understanding probabilistic system design, evaluation methodologies, and how errors compound in multi-step AI workflows
AI Engineering emerges as a specialized role - MLOps and data science practitioners have advantages since they already work with probabilistic systems, creating opportunities for this new career path.
Organizations need company-wide evaluation practices - Successful GenAI adoption requires establishing systematic audit and evaluation frameworks across the organization, not just individual developer skills
Introduction
Following a strategy that Microsoft spearheaded in the 90s, OpenAI and all other major AI labs have put considerable effort in guaranteeing that their API ecosystems are readily adopted by developers across the globe. As such, developers have become notable champions for the successful adoption of GenAI, giving a considerable advantage to companies that already have robust internal development practices.

At first glance, it seems that developers are well-equipped to embed GenAI in their applications, since they’re only required to learn some basic prompting techniques. In this post I’ll argue that the requirements are substantially larger, requiring a clear understanding of how probabilistic and deterministic systems are built and tested.1 This makes the AI engineer a better suited role for the task.
Probabilistic and deterministic systems: a primer
The behavior of deterministic systems is certain by design. This means that given some inputs, the developer can predict the output with certainty. This prediction or tracking can be quite complex — as anyone who has tried to debug a script can attest — but in principle this can be done without error.
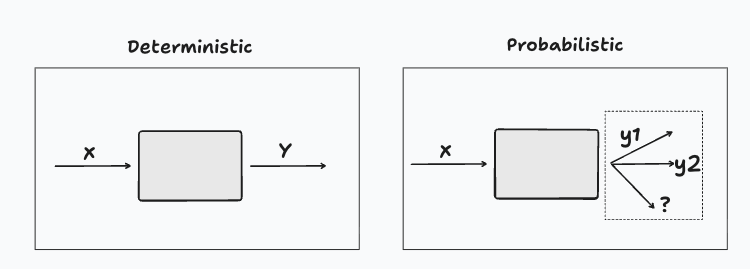
Probabilistic systems are inherently uncertain, so given certain inputs, it’s impossible to predict their output with complete certainty. These types of systems are less known and used in real-life applications, but they do have a long history of practical use cases and are the bread and butter of machine learning operations (MLOps) and data science practitioners.
Importantly, GenAI is probabilistic, so any system that uses this technology will inherit its probabilistic nature.
Hello World!
A simple example of a deterministic system is shown next. For any given number (input) the system uses the following decision rule: if it’s divisible by two, it outputs “Hello World!”. Otherwise it outputs “Salutations!”
def deterministic_hello(input_value):
if input_value % 2 == 0:
return "Hello World!"
else:
return "Salutations!"A probabilistic analog includes randomness by design, as the following example shows. This function draws a uniform pseudo-random number, and depending on the value of this draw it applies one rule or another. In both cases there’s a decision rule, but the one in this example has some randomness embedded.
import random
def probabilistic_hello():
rand = random.random()
if rand < 0.5:
return "Hello World!"
else:
return "Salutations!"
Testing and evaluations
Unit testing is one of the quintessential tools used to ensure that deterministic systems work as planned. The idea is simple:
Software is split in units (say a function, like the ones in the examples above). These units are the smallest pieces of code that do something on their own.
These units are assembled into complex scripts and codebases.
Instead of testing the whole system (hard to debug), the developer runs repeatable (and replicable) tests on the units.
Naturally, the system also requires a full end-to-end integration test, but if all of the units have already been independently tested, any remaining errors are easier to debug.
Probabilistic systems require a different approach, as the following coin-flipping example shows. You flip a coin and want to test if the coin is balanced.2 A “unit-test” consists of one toss, and you check if it falls on head or tail. Naturally, from this result you can’t conclude that it’s balanced. You need to repeat this test many times, record the results and then check the proportion of trials with heads and tails.
This is the logic underlying evaluations (also called evals) of probabilistic systems. You need to start by defining a metric (e.g. accuracy, faithfulness, etc.). And then you create a dataset that allows for repeated measurements that are then averaged or aggregated in some other way. This part requires quite a bit of work, and can be done by humans or using LLMs.
Example: LLM categorization
When a customer contacts a call center, she’s asked to start by categorizing the type of request among several preset options. We found that this categorization had a high error rate, leading to longer resolution times. We decided to take the comments left by the customer, and use an LLM to categorize it.
This is a pretty straightforward use case, but without a proper evaluation scheme it was hard to know if the LLM was doing a better job. We decided to create a “certified dataset” where humans did a thorough first-pass categorization. This certified dataset was used to evaluate the overall performance of the LLM-based application. We used accuracy as the evaluation metric.
Example: LLM matching
In another application we used LLMs to match job descriptions (JD) for open positions with candidate CVs. Specifically, for a given JD the application would rank (and score) the candidates using their CV. This was used as a first automated stage to filter out candidates who were not a good fit for the position, based on their experience.
Here we decided to create a synthetic dataset of JDs and CVs. We first used an LLM to create a JD. For this JD, we used an LLM to create two CVs: an ideal one (the perfect fit for the position), and one that’s not ideal because it lacked at least one of the requisite experiences. We decided to use top-1 and top-5 accuracy metrics.
Example: LLM-as-a-judge
An LLM is used to take notes from a meeting, summarize and create next steps to be shared. One way to evaluate this application is by using a larger model to evaluate the output from the other model.
Agentic workflows
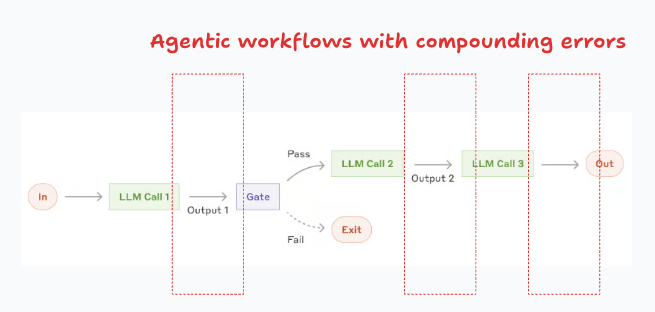
Composability is another key concept when designing deterministic systems. As the name suggests, larger systems can be built (composed) from the smaller units. Composability is also applied to probabilistic systems, and any errors propagate to the larger system.
In agentic workflows multiple LLMs are chained in such a way that errors may compound, potentially reducing the quality of the outputs. You don’t need complex workflows to see how this works. The next figure (from Anthropic) shows a relatively straightforward “prompt chaining workflow” where an LLM uses as input the output from an LLM in a previous step.
What next?
Probabilistic systems create important challenges for organisations that are embarking on their GenAI adoption path. From an organisation point of view, it’s important to define company-wide evaluation and audit practices.
From an individual perspective, in this post I argue that software developers lack some of the critical skills required to build probabilistic systems. Learning to think about probabilistic systems requires practice, and MLOps and data science practitioners already have an advantage since this is part of their day-to-day workflows. The new role of AI engineering creates opportunities for skill development and career progression for all of these.
As a case example, companies like Amazon or Apple have struggled to embed GenAI in their own systems. Check out this Hard Fork podcast episode (minute 25:18 where they discuss Alexa +)
A balanced coin has equal probability of landing on heads or tails.