
Finding the Right Data for Your Problem (part 2)
Embracing the broader concept of dataset engineering

TL;DR
The Data Processing Inequality sets theoretical limits on dataset engineering: no transformation can increase the information content about outcomes, only make existing information more accessible to algorithms.
Data augmentation techniques like oversampling minority classes and label-preserving transforms help algorithms learn patterns that would otherwise be difficult to detect, though gaps remain between practice and theory.
Feature engineering encompasses creating, selecting, and transforming variables to improve predictive performance, from manual ratio construction to automated deep learning representations.
Classical manual feature engineering is giving way to automated approaches, with deep learning architectures automatically discovering useful representations through overparameterization.
While dataset engineering shows promise, it remains unclear whether automated approaches will fully deliver on the data-centric AI vision of systematically producing optimal datasets.
Prelude
Leo Breiman’s (2001) “Statistical Modeling: The Two Cultures” compared two different approaches to predictive modeling: the data-modeling school that makes strong assumptions about the data generating process (DGP) to ensure desirable (usually long-run convergence) properties, and the algorithmic-modeling school that puts more focus on algorithms and predictive performance. Breiman criticizes the overreliance on restrictive data models over possibly black-box but superior predictive performance.
In the first part of this series I argued that many data scientists fail to acknowledge the importance of understanding the sources of variation that are required for their predictive problem. Since variation is usually better understood at the row level of a dataset, I argued for thinking hard about the required granularity for the problem, itself relying on thinking hard about the DGP. In the light of Breiman’s article this might feel like a regression to “darker” times.
Interestingly, in the last couple of years, the data-centric AI movement has been pushing for bringing back the focus to the data, and away from the algorithms. The approach calls for a “systematic engineering of the data” to ensure the development of successful AI systems. Specifically, “model-centric AI is based on the goal of producing the best model for a given dataset, whereas data-centric AI is based on the goal of systematically & algorithmically producing the best dataset to feed a given ML model.” 1
In this post I’ll start first by discussing the theoretical limits of dataset engineering, as presented by the Data Processing Inequality, and then discuss some other notable characteristics and examples of the broader theme of dataset engineering.
The Data Processing Inequality
Consider a set of features X and an outcome Y. The Data Processing Inequality is a very nice theorem in information theory that can be paraphrased as:2
Data Processing Inequality
No transformation of X can increase the amount of information it already contains about outcome Y, and in fact, some of it can actually be lost.
In other words, no matter how much you transform your dataset, this will not increase the amount of information that the raw features already have about the outcome.
So does this imply that all efforts to better engineer the dataset can only lead to worse predictive performance? The answer is a resounding no: training algorithms benefit from data transformations that facilitate the process of extracting information. The key distinction is that the theorem discusses the upper limit of information extraction, but in practice, algorithms are far from approaching that limit.3
So dataset engineering — for the lack of a better term — is a valuable set of techniques that can improve the overall performance of machine learning algorithms. I’ll now continue reviewing some of these techniques.
Data augmentation
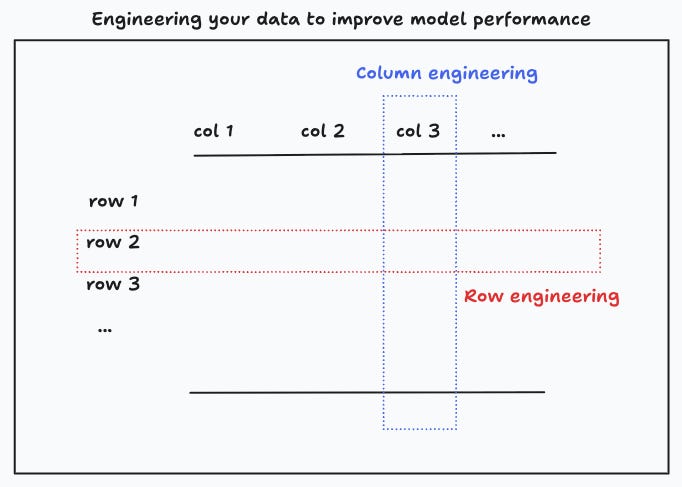
One way to engineer the dataset is by augmenting it so that the algorithm can learn important features that would otherwise be hard to detect. Thinking in terms of tabular data, this means increasing the number of rows, with the objective of injecting information that can help the algorithm uncover significant patterns.
A common example can be found in unbalanced classification problems, where one of the labels is substantially underrepresented (say “this transaction is fraudulent”), and the data scientist decides to augment the data by oversampling the minority class. By doing this, the learning algorithm can efficiently allocate time to learning features for the minority and majority classes.
Similarly, in deep learning applications it’s common to create synthetic data to ensure robustness or invariance of the algorithm. In computer vision applications, datasets are commonly augmented using “label-preserving transforms”. For example, in an image classifier, you can rotate, crop or blur an image of a dog, and the classifier should remain robust to these transformations. Similarly, in LLMs you can augment the data by preserving the meaning of a sentence.

There are many approaches to data augmentation, and there’s still a gap between the practice and the theoretical understanding of why and when some of these work.4 For instance, in the Mixup technique you create new instances of your data by literally mixing or combining them, so that if your dataset has a picture of a dog and a picture of a cat, you can create a new instance that is, say, 60% of a dog and 40% of a cat.5 Presumably this works by smoothing the decision boundary.6

Feature engineering
Feature engineering can be defined as the process of creating, selecting, transforming or combining input variables to improve the predictive performance of a machine learning algorithm. In tabular data, a feature is commonly taken to be a column, but one can more generally think of features as inputs to make a prediction.7 Typical feature transformations include the construction of new features from ratios, products and polynomial terms, scaling, normalization, and so on.8
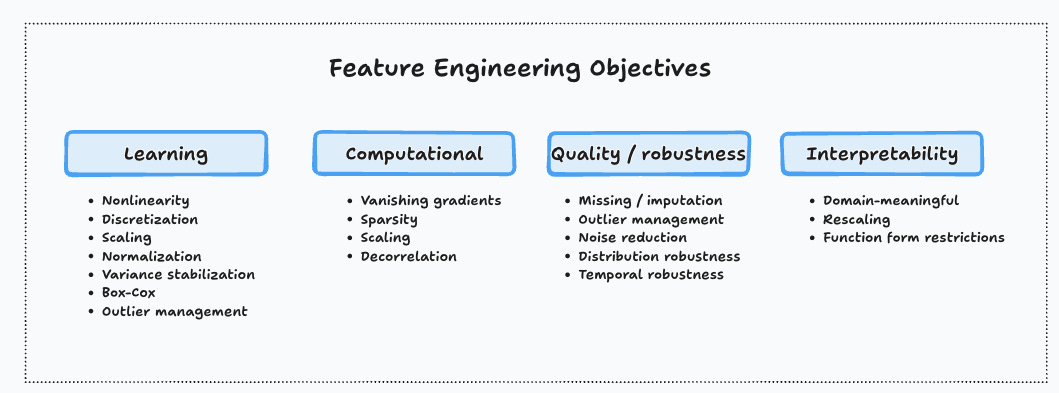
Feature engineering is a multifaceted set of techniques that can help you achieve faster learning or better predictive performance (e.g. nonlinearity), avoid computational pitfalls (e.g. vanishing gradients), improve the quality and robustness of your predictions, or make the model more interpretable.
Classical feature engineering is a manual process that can be somewhat automated in specific instances.9 Deep learning, with its focus on learning latent representations, is a different approach, where features are automatically discovered by sufficiently flexible architectures that allow for overparameterization.
What’s next
Feature engineering is well understood by most practitioners, and it’s part of the expected skill set for data scientists of all levels.10 More generally, practitioners should learn and apply techniques of dataset engineering. To be sure, at this point it’s unclear if the data-centric vision of automated dataset engineering delivers on its promise.11
In the final post of this series I’ll discuss the role that variation plays in causal inference, and more importantly, how this forces you to think about the ideal dataset for the task.
The quote is from these lecture notes from MIT. Passages in bold and italics are in the original text. A somewhat recent survey can be found in Zha et al. (2023).
For random variables X,Y and Z that form a Markov chain X → Y → Z, the data processing inequality states that I(X;Z) ≤ I(X;Y), where I(A;B) is the mutual information between A and B.
Algorithms have inductive biases and are restricted by computational constraints and optimization challenges that prevent them from achieving the theoretical maximum. Furthermore, the no free lunch theorem reminds us that there’s no universally superior algorithm that applies to all problems.
A recent survey of data augmentation techniques can be found in Wang et al. (2025). Note that data augmentation has potential downsides that include overfitting to augmentation samples, computational overhead and the risk of introducing unrealistic samples.
More precisely, consider a new figure that consists of 60% of dog image pixels and 40% of cat image pixels, and a corresponding label of [0.6, 0.4].
Zhang et al. (2020) argue that mixup makes the algorithm more robust to adversarial attacks, providing superior generalization, and show that training under mixup is equivalent to a type of regularization.
In his “Feature Engineering Bookcamp”, Sinan Ozdemir defines a feature as “an attribute or column of data that is meaningful to an ML model”. The more general definition can be found in Hastie et al., “The Elements of Statistical Learning”. This more general definition translates nicely to deep learning and learned representations.
There are many good references on the subject of feature engineering, see e.g. Soledad Galli’s “Python Feature Engineering Cookbook”.
For example, automated approaches to find polynomial bases and model nonlinear relationships have been in the literature for decades.
For instance, Chapter 9 in Gonzalez and Stubberfield (2024), “Cracking the Data Science Interview: Unlock insider tips from industry experts to master the data science field“ covers the topics of feature engineering and data preparation.
Arguably, the AutoML movement has failed to deliver on its promise, but new approaches like AutoAugment might shed some light into how combining methods of reinforcement learning can help in such automation efforts.